RLHF is the standard approach for aligning LLMs. However, recent advances in offline alignment methods, such as direct preference optimization (DPO) and its variants, challenge the necessity of on-policy sampling in RLHF. Offline methods, which align LLMs using pre-existing datasets without active online interaction, have shown practical efficiency and are simpler and cheaper to implement. This raises the question of whether online RL is essential for AI alignment. Comparing online and offline methods is complex due to their different computational demands, necessitating careful calibration of the budget spent to measure performance fairly.
Researchers from Google DeepMind demonstrated that online methods outperform offline methods in their initial experiments, prompting further investigation into this performance gap. Through controlled experiments, they found that factors like offline data coverage and quality must fully explain the discrepancy. Unlike online methods, offline methods excel in pairwise classification but need help with generation. The gap persists regardless of loss function type and model scaling. This suggests that on-policy sampling is crucial for AI alignment, highlighting challenges in offline alignment. The study uses KL divergence from the supervised fine-tuned (SFT) policy to compare performance across algorithms and budgets, revealing persistent differences.
The study complements previous work on RLHF by comparing online and offline RLHF algorithms. The researchers identify a persistent performance gap between online and offline methods, even when using different loss functions and scaling policy networks. While previous studies noted challenges in offline RL, their findings emphasize that they extend to RLHF.
The study compares online and offline alignment methods using the IPO loss across various datasets, examining their performance under Goodhart’s law. The IPO loss involves optimizing the weight of winning responses over losing ones, with differences in sampling processes defining the online and offline methods. Online algorithms sample responses on policy, while offline algorithms use a fixed dataset. Experiments reveal that online algorithms achieve better trade-offs between KL divergence and performance, using the KL budget more efficiently and achieving higher peak performance. Several hypotheses are proposed to explain these discrepancies, such as data coverage diversity and sub-optimal offline datasets.
The hypothesis posits that the performance discrepancy between online and offline algorithms can be partially attributed to the classification accuracy of the proxy preference model compared to the policy itself. Firstly, the proxy preference model tends to achieve higher classification accuracy than the policy when used as a classifier. Secondly, it proposes that this difference in classification accuracy contributes to the observed performance gap between online and offline algorithms. In essence, it suggests that better classification leads to better performance, but this hypothesis needs to be further examined and validated through empirical evidence.
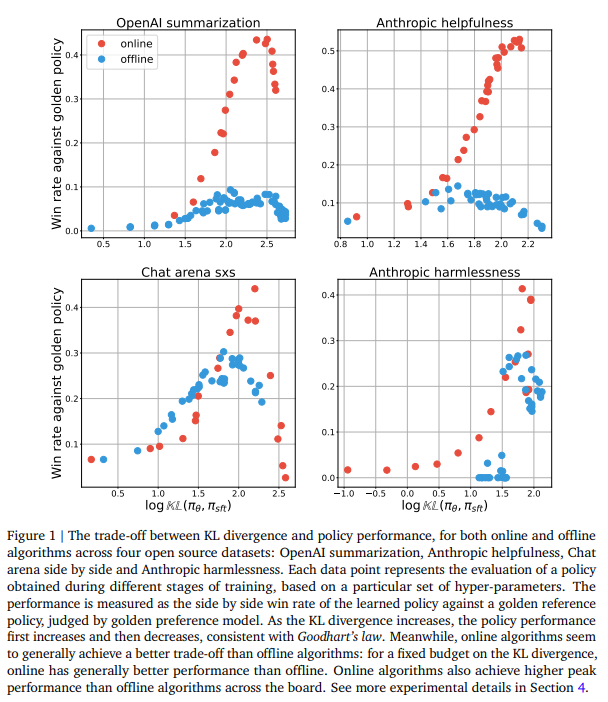
In conclusion, the study highlights the critical role of on-policy sampling in effectively aligning LLMs and exposes the challenges associated with offline alignment approaches. The researchers debunked several commonly held beliefs about the performance gap between online and offline algorithms through rigorous experimentation and hypothesis testing. They emphasized the importance of on-policy data generation for enhancing policy learning efficiency. However, they also argue that offline algorithms can improve by adopting strategies that mimic online learning processes. This opens avenues for further exploration, such as hybrid approaches combining the strengths of both online and offline methods and deeper theoretical investigations into reinforcement learning for human feedback.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
