Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing (NLP) tasks, such as machine translation and question-answering. However, a significant challenge remains in understanding the theoretical underpinnings of their performance. Specifically, there is a lack of a comprehensive framework that explains how LLMs generate contextually relevant and coherent sequences of text. This challenge is compounded by limitations such as fixed vocabulary size and context windows, which constrain the full comprehension of the token sequences LLMs can process. Addressing this challenge is essential to optimize LLMs’ efficiency and expand their real-world applicability.
Previous studies have focused on the empirical success of LLMs, particularly those built on the transformer architecture. While these models perform well in tasks involving sequential token generation, existing research has either simplified their architectures for theoretical analysis or neglected the temporal dependencies inherent in token sequences. This limits the scope of their findings and leaves gaps in our understanding of how LLMs generalize beyond their training data. Moreover, no framework has successfully derived theoretical generalization bounds for LLMs when handling temporally dependent sequences, which is crucial for their broader application in real-world tasks.
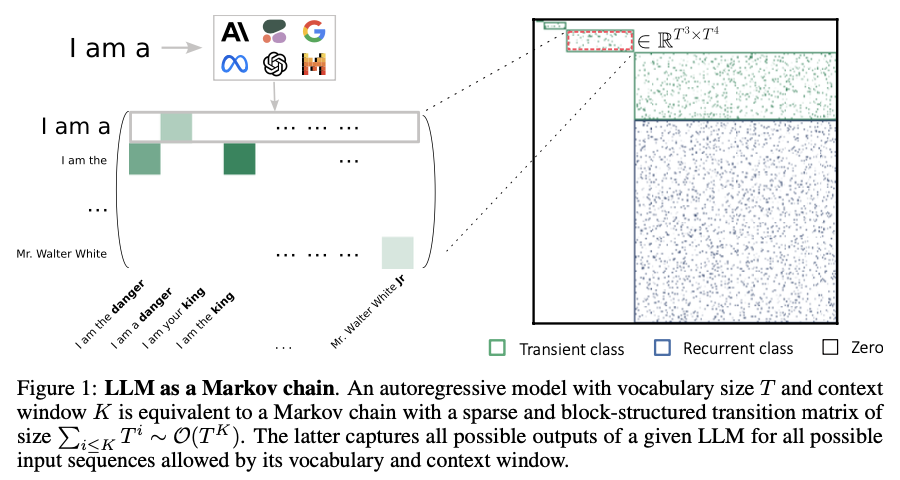
A team of researchers from ENS Paris-Saclay, Inria Paris, Imperial College London, and Huawei Noah’s Ark Lab introduces a novel framework by modeling LLMs as finite-state Markov chains, where each input sequence of tokens corresponds to a state, and transitions between states are determined by the model’s prediction of the next token. This formulation captures the full range of possible token sequences, providing a structured way to analyze LLM behavior. By formalizing LLMs through this probabilistic framework, the study offers insights into their inference capabilities, specifically the stationary distribution of token sequences and the speed at which the model converges to this distribution. This approach represents a significant advancement in understanding how LLMs function, as it provides a more interpretable and theoretically grounded foundation.
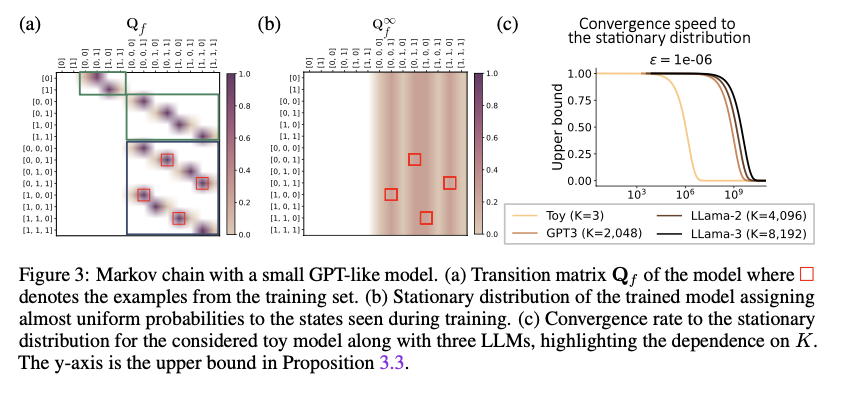
This method constructs a Markov chain representation of LLMs by defining a transition matrix Qf, which is both sparse and block-structured, capturing the model’s potential output sequences. The size of the transition matrix is O(T^k), where T is the vocabulary size, and K is the context window size. The stationary distribution derived from this matrix indicates the LLM’s long-term prediction behavior across all input sequences. The researchers also explore the influence of temperature on the LLM’s ability to traverse the state space efficiently, showing that higher temperatures lead to faster convergence. These insights were validated through experiments on GPT-like models, confirming the theoretical predictions.
Experimental evaluation on various LLMs confirmed that modeling them as Markov chains leads to more efficient exploration of the state space and faster convergence to a stationary distribution. Higher temperature settings notably improved the speed of convergence, while models with larger context windows required more steps to stabilize. Additionally, the framework outperformed traditional frequentist approaches in learning transition matrices, especially for large state spaces. These results highlight the robustness and efficiency of this approach in providing deeper insights into LLM behavior, particularly in generating coherent sequences applicable to real-world tasks.
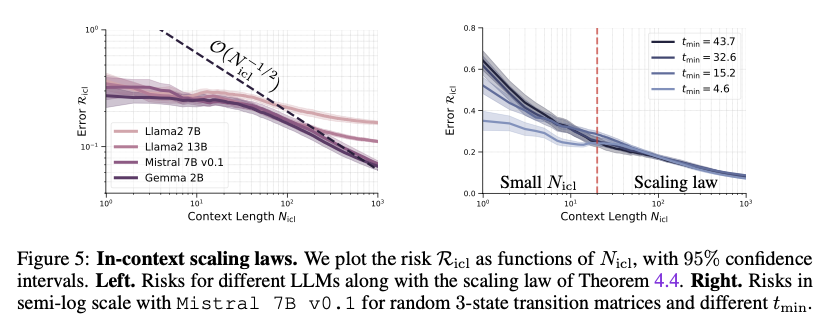
This study presents a theoretical framework that models LLMs as Markov chains, offering a structured approach to understanding their inference mechanisms. By deriving generalization bounds and experimentally validating the framework, the researchers demonstrate that LLMs are highly efficient learners of token sequences. This approach significantly enhances the design and optimization of LLMs, leading to better generalization and improved performance across a range of NLP tasks. The framework provides a robust foundation for future research, particularly in examining how LLMs process and generate coherent sequences in diverse real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
