The efficacy of deep reinforcement learning (RL) agents critically depends on their ability to utilize network parameters efficiently. Recent insights have cast light on deep RL agents’ challenges, notably their tendency to underutilize network parameters, leading to suboptimal performance. This inefficiency is not merely a technical hiccup but a fundamental bottleneck that curtails the potential of RL agents in complex domains.
The problem is the need for more utilization of network parameters by deep RL agents. Despite the remarkable successes of deep RL in various applications, evidence suggests these agents often fail to harness the full potential of their network’s capacity. This inefficiency manifests in dormant neurons during training and an implicit underparameterization, leading to a significant performance gap in tasks requiring intricate reasoning and decision-making.
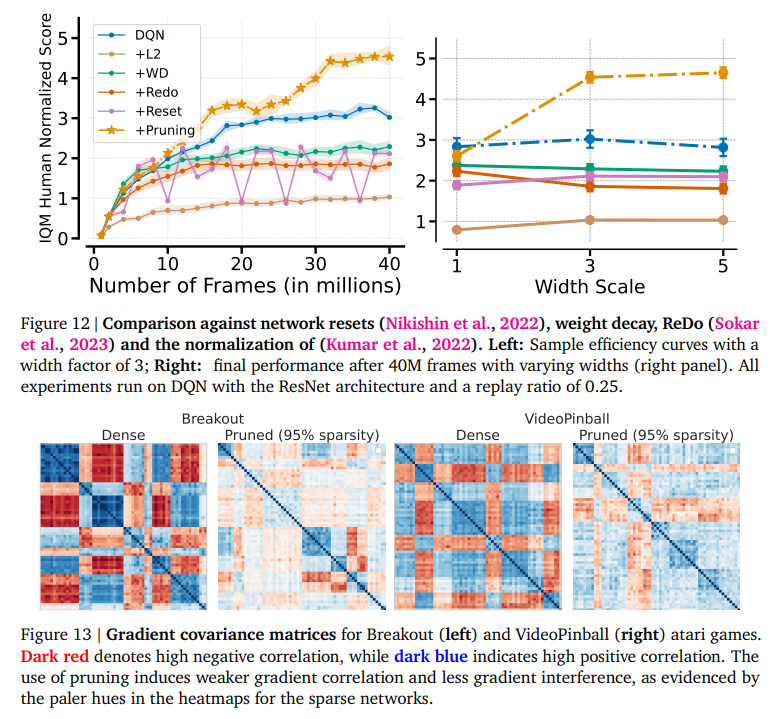
While pioneering, current methodologies in the field grapple with this challenge to varying degrees of success. Sparse training methods have shown promise, which aims to streamline network parameters to essential ones. However, these methods often lead to a trade-off between sparsity and performance without fundamentally addressing the root cause of parameter underutilization.
The study by researchers from Google DeepMind, Mila – Québec AI Institute, and Université de Montréal introduces a groundbreaking technique known as gradual magnitude pruning, which meticulously trims down the network parameters, ensuring that only those of paramount importance are retained. This approach is rooted in the understanding that dormant neurons and underutilized parameters significantly hamper the efficiency of a network. This phenomenon restricts the agent’s learning capacity and inflates computational costs without commensurate benefits. By applying a principled strategy to increase network sparsity gradually, the research unveils an unseen scaling law, demonstrating that judicious pruning can lead to substantial performance gains across various tasks.

Networks subjected to gradual magnitude pruning consistently outperformed their dense counterparts across a spectrum of reinforcement learning tasks. This was not limited to simple environments but extended to complex domains requiring sophisticated decision-making and reasoning. The method’s efficacy was particularly pronounced when traditional dense networks struggled, underscoring the potential of pruning to unlock new performance levels in deep RL agents.
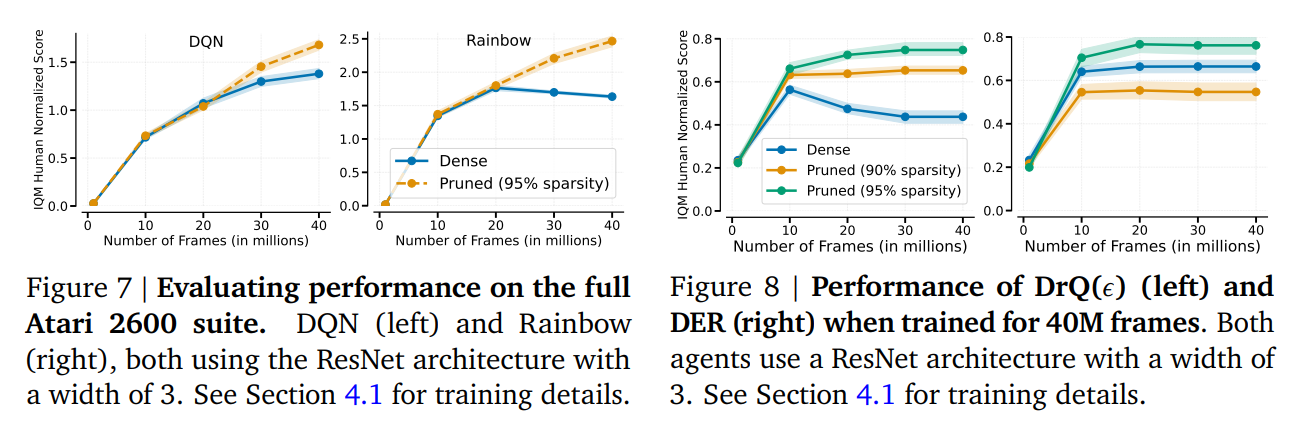
By significantly reducing the number of active parameters, gradual magnitude pruning presents a sustainable path toward more efficient and cost-effective reinforcement learning applications. This approach aligns with making AI technologies more accessible and reducing their environmental impact, a consideration of increasing importance in the field.
In conclusion, the contributions of this research are manifold, offering new perspectives on optimizing deep RL agents:
- Introduction of gradual magnitude pruning: A novel technique that maximizes parameter efficiency, leading to significant performance improvements.
- Demonstration of a scaling law: Unveiling the relationship between network size and performance, challenging the prevailing notion that bigger networks are inherently better.
- Evidence of general applicability: Showing the technique’s effectiveness across various agents and training regimes, suggesting its potential as a universal method for enhancing deep RL agents.
- Alignment with sustainability goals: Proposing a path towards more environmentally friendly and cost-effective AI applications by reducing computational requirements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
