Large language models (LLMs) have shown remarkable capabilities in NLP, performing tasks such as translation, summarization, and question-answering. These models are essential in advancing how machines interact with human language, but evaluating their performance remains a significant challenge due to the immense computational resources required.
One of the primary issues in evaluating LLMs is the high cost associated with using extensive benchmark datasets. Traditionally, benchmarks like HELM and AlpacaEval consist of thousands of examples, making the evaluation process computationally expensive and environmentally and financially demanding. For instance, evaluating a single LLM on HELM can cost over 4,000 GPU hours, translating to over $10,000. These high costs hinder the ability to frequently assess and improve LLMs, especially as these models grow in size and complexity.
Existing methods for evaluating LLMs involve using large-scale benchmarks such as MMLU, which contains approximately 14,000 examples. While these benchmarks are comprehensive, they could be more efficient. They have been exploring ways to reduce the number of examples needed for accurate evaluation. This is where the concept of “tinyBenchmarks” comes into play. By focusing on a curated subset of examples, researchers aim to maintain accuracy while significantly reducing the cost and time required for evaluation.
The research team from the University of Michigan, the University of Pompeu Fabra, IBM Research, MIT, and the MIT-IBM Watson AI Lab introduced tinyBenchmarks. These smaller versions of popular benchmarks are designed to provide reliable performance estimates using fewer examples. For example, their analysis showed that evaluating an LLM on just 100 curated examples from the MMLU benchmark can predict its performance with an average error of under 2%. This approach drastically reduces the resources needed for evaluation while providing accurate results.
The researchers used several strategies to develop these tinyBenchmarks. One method involves stratified random sampling, where examples are chosen to represent different data groups evenly. Another approach is clustering based on model confidence, where examples likely to be correctly or incorrectly predicted by the LLM are grouped. The team applied item response theory (IRT), a statistical model traditionally used in psychometrics, to measure the latent abilities required to respond to benchmark examples. By clustering these representations, they created robust evaluation sets that could effectively estimate performance.
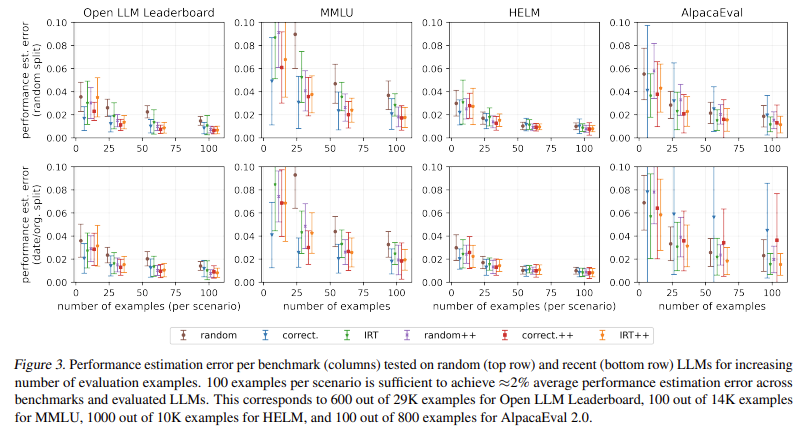
The proposed method has demonstrated effectiveness across various benchmarks, including the Open LLM Leaderboard, HELM, and AlpacaEval 2.0. By evaluating LLMs on just 100 examples, the researchers achieved reliable performance estimates with an error margin of around 2%. This significant reduction in the number of required examples translates to substantial savings in computational and financial costs.
The performance of these tinyBenchmarks was further validated through extensive testing. For instance, the accuracy of predictions on the MMLU benchmark using only 100 examples was within 1.9% of the true accuracy across all 14,000. This level of precision confirms that tinyBenchmarks are efficient and highly reliable. The research team has publicly made these tools and datasets available, allowing other researchers and practitioners to benefit from their work.

In conclusion, tinyBenchmarks addresses the high computational and financial costs associated with traditional benchmarks by reducing the number of examples needed for accurate performance estimation. The research provides a practical solution for frequent and efficient evaluation of LLMs, enabling continuous improvement in NLP technologies.
Check out the Paper, GitHub, HF Models, and Colab Notebook. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

