
Together AI has unveiled a groundbreaking advancement in AI inference with its new inference stack. This stack, which boasts a decoding throughput four times faster than the open-source vLLM, surpasses leading commercial solutions like Amazon Bedrock, Azure AI, Fireworks, and Octo AI by 1.3x to 2.5x. The Together Inference Engine, capable of processing over 400 tokens per second on Meta Llama 3 8B, integrates the latest innovations from Together AI, including FlashAttention-3, faster GEMM and MHA kernels, and quality-preserving quantization, as well as speculative decoding techniques.
Additionally, Together AI has introduced the Together Turbo and Together Lite endpoints, starting with Meta Llama 3 and expanding to other models shortly. These endpoints offer enterprises a balance of performance, quality, and cost-efficiency. Together Turbo provides performance that closely matches full-precision FP16 models, making it the fastest engine for Nvidia GPUs and the most accurate, cost-effective solution for building generative AI at production scale. Together Lite endpoints leverage INT4 quantization for the most cost-efficient and scalable Llama 3 models available, priced at just $0.10 per million tokens, which is six times lower than GPT-4o-mini.
The new release includes several key components:
- Together Turbo Endpoints: These endpoints offer fast FP8 performance while maintaining quality that closely matches FP16 models. They have outperformed other FP8 solutions on AlpacaEval 2.0 by up to 2.5 points. Together Turbo endpoints are available at $0.18 for 8B and $0.88 for 70B models, which is 17 times lower in cost than GPT-4o.
- Together Lite Endpoints: Utilizing multiple optimizations, these endpoints provide the most cost-efficient and scalable Llama 3 models with excellent quality relative to full-precision implementations. The Llama 3 8B Lite model is priced at $0.10 per million tokens.
- Together Reference Endpoints: These provide the fastest full-precision FP16 support for Meta Llama 3 models, achieving up to 4x faster performance than vLLM.
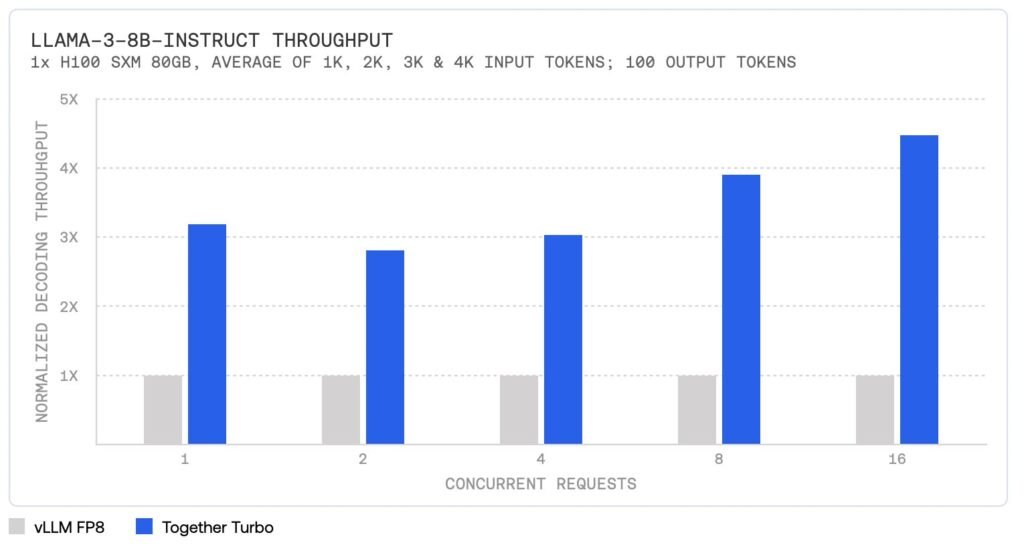
- The Together Inference Engine integrates numerous technical advancements, including proprietary kernels like FlashAttention-3, custom-built speculators based on RedPajama, and the most accurate quantization techniques on the market. These innovations ensure leading performance without sacrificing quality. Together Turbo endpoints, in particular, provide up to 4.5x performance improvement over vLLM on Llama-3-8B-Instruct and Llama-3-70B-Instruct models. This performance boost is achieved through optimized engine design, proprietary kernels, and advanced model architectures like Mamba and Linear Attention techniques.
- Cost efficiency is another major advantage of the Together Turbo endpoints, which offer more than 10x lower costs than GPT-4o and significantly reduce costs for customers hosting their dedicated endpoints on the Together Cloud. On the other hand, Together Lite endpoints provide a 12x cost reduction compared to vLLM, making them the most economical solution for large-scale production deployments.
- The Together Inference Engine continuously incorporates cutting-edge innovations from the AI community and Together AI’s in-house research. Recent advancements like FlashAttention-3 and speculative decoding algorithms, such as Medusa and Sequoia, highlight the ongoing optimization efforts. Quality-preserving quantization ensures that even with low precision, the performance and accuracy of models are maintained. These innovations offer the flexibility to scale applications with the performance, quality, and cost-efficiency that modern businesses demand. Together AI looks forward to seeing the incredible applications that developers will build with these new tools.
Check out the Detail. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here


Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.