

State-of-the-art large language models (LLMs) are increasingly conceived as autonomous agents that can interact with the real world using perception, decision-making, and action. An important topic in this arena is whether or not these models can effectively use external tools. Tool use in LLMs will involve:
- Recognizing when a tool is needed.
- Choosing the correct tools.
- Executing actions that accomplish these tasks.
Some of the key issues to be tackled in the pursuit of going beyond previous milestones with LLMs relate to the precise evaluation of their capabilities for tool-use in a real-world setting. The standard evaluation benchmarks for most such systems handle, at best, static, single-turn settings by which it means situations that do not solicit stateful, multi-turn responses requiring the model to retain past interaction details and contextual changes. The lack of comprehensive evaluation frameworks implies that it can be difficult to judge how effectively such models can perform tasks requiring external tools, particularly in dynamic and interactive environments where actions taken by the model may lead to cascading effects on the state of the world.
Several benchmark collections for evaluation, such as BFCL, ToolEval, and API-Bank, have been developed to measure LLM tool-use capabilities. These benchmarks have been designed to assess the capabilities of the models to interact with Web services in combination with function-call scenarios. The benchmarks suffer from several limitations, though. One is that both BFCL and ToolEval work on stateless interactions. That is, the actions of the model do not alter the environment. Secondly, while API-Bank contains state-dependent tools, it also needs to adequately examine the impact of state dependencies on the execution of initiated tasks. These limitations result in an incomplete understanding of how well LLMs can manage complex, real-world tasks involving multiple steps and environmental interactions.

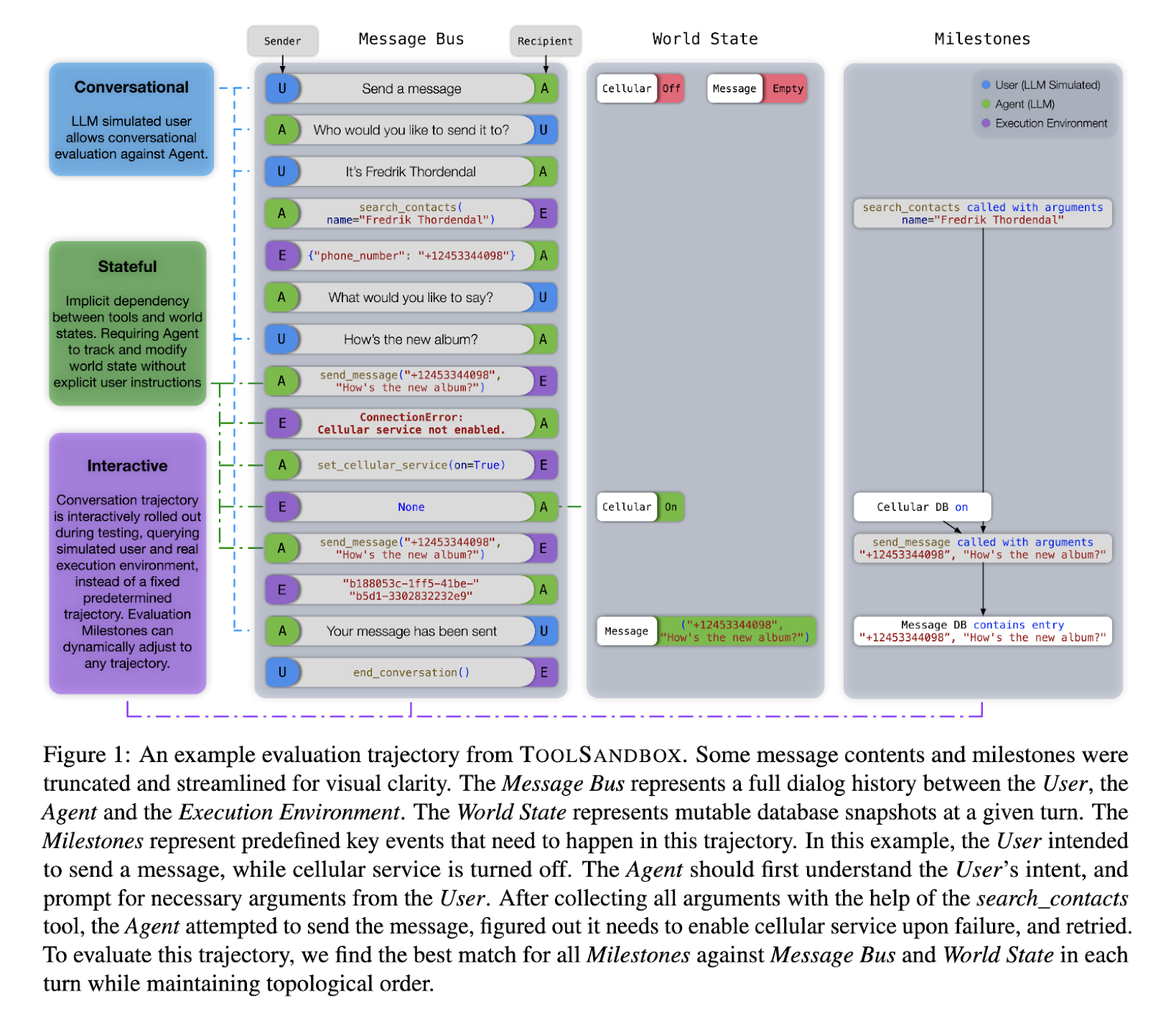
The Apple research team addressed these challenges by introducing a new benchmark for evaluation: ToolSandbox is designed to evaluate the specific tool-use capabilities of LLMs in stateful and interactive conversational settings. ToolSandbox would allow for a much richer evaluation environment, which includes state-dependent tool execution, implicit state dependencies, and on-policy conversational evaluation with a simulated user; thus, this will allow for an in-depth evaluation of how suitable the LLMs are for real-world and complex tasks that involve many interactions and decisions based on the actual state of an environment.
The ToolSandbox framework creates a Python-based execution environment in which LLMs interact with a simulated user and a set of tools to complete tasks. The world state is held in the environment, and its actions are measured against predefined milestones and minefields in the model. The former consists of critical steps the model must reach to complete the task, while the latter consists of an event that the model should not carry out. The framework will thereby allow the evaluation to continuously adapt to the model’s performance, enabling an analysis of how well the model can adapt to environmental changes & how well it can carry out multitask operations with interconnected steps and dependencies.
The most important innovation that sets ToolSandbox apart from existing benchmarks is the introduction of stateful tools that depend on the current state of the world to operate as expected. Take a messaging tool that sends a message: this will only work if the cell phone service is on, and there might be other preconditions to consider, such as battery level. It also incorporates an LLM-based user simulator where interactions with the model are conducted in a lifelike, on-policy manner, a more realistic evaluation of its power under real-life conditions. What is more, the framework allows for the augmentation of tool names and descriptions of various scrambling tools to, in turn, test the resulting robustness of the model’s tool-use capabilities.

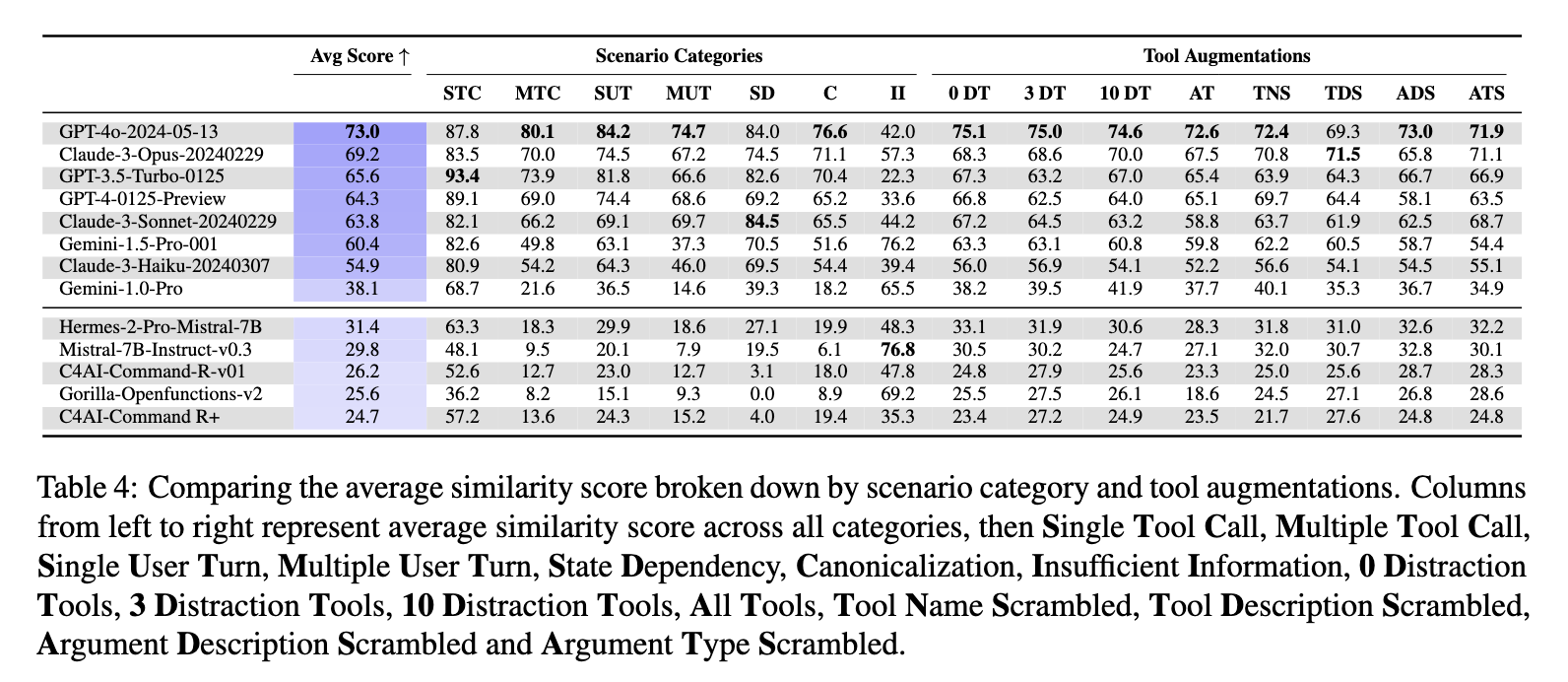
The ToolSandbox benchmark has revealed performance differences among various LLMs, highlighting significant discrepancies between proprietary and open-source models. Proprietary models such as OpenAI’s GPT-4o and Anthropic’s Claude-3-Opus outperformed other models, achieving higher similarity scores in several use cases. In contrast, open-source models like Hermes-2-Pro-Mistral-7B struggled with complex tasks involving state dependencies and canonicalization. For instance, in a canonicalization task where the model standardizes user input, GPT-4o achieved a similarity score of 73.0, while Hermes-2-Pro-Mistral-7B scored only 31.4. The benchmark also highlighted challenges related to insufficient information scenarios, where a model must identify the need for the correct tool or data to perform a task without generating incorrect tool calls or arguments.
In this respect, ToolSandbox stands as a notable progress in the benchmarking process of LLM tool-use capabilities, providing an evaluation framework that is more comprehensive and realistic than before. Emphasizing the stateful and interactive nature of the task, ToolSandbox yields multiple insights valuable to understanding LLMs’ abilities and limitations on real-world applications. The results of this benchmark suggest further work and development in this direction, particularly at LLM robustness and adaptability to deal with intricate and multistep interactions that continually change.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

