Generative models are designed to replicate the patterns in the data they are trained on, typically mirroring human actions and outputs. Since these models learn to minimize the difference between their predictions and human-generated data, they aim to match the quality of human expertise in various tasks, such as answering questions or creating art. This raises a question: can these models exceed the proficiency of the expert sources they learn from, given their goal is merely to imitate human performance rather than innovate beyond it?
Researchers from Harvard University, UC Santa Barbara, Apple, the Kempner Institute, Princeton University, and Google DeepMind explored “transcendence” in generative models, where a model surpasses the abilities of its expert data sources. Using an autoregressive transformer trained on chess game transcripts, they demonstrated that the model could outperform the maximum rating of players in the dataset through low-temperature sampling. This process aligns with the “wisdom of the crowd,” where the collective decision-making of diverse experts often surpasses individual performance. The study provides a theoretical framework and empirical evidence showing that such generative models can enhance performance.
Chess has been integral to AI development since its inception, with early explorations by Claude Shannon and Alan Turing. The game continues to inspire advances, leading to the defeat of world champion Garry Kasparov by IBM’s Deep Blue in 1997 and the dominance of AlphaZero’s RL-based approach over previous engines like Stockfish. The study connects with AI diversity research, showing that models trained on diverse datasets outperform individual expert-based models through ensemble methods and low-temperature sampling. Additionally, the concept is tied to Offline Reinforcement Learning, where training on varied behavior can lead to policies surpassing the original training data’s performance.
Transcendence in generative models occurs when a model outperforms the experts on which it was trained. This is defined mathematically by comparing the model’s average reward on a test distribution to the rewards of the experts. Low-temperature sampling is a key factor enabling transcendence, which concentrates probability mass on high-reward actions, effectively simulating a majority vote among expert predictions. This denoising effect can surpass individual expert performance, especially in settings with multiple experts who excel in different areas. Additionally, even a noisy expert can achieve transcendence through careful sampling, emphasizing the expert’s optimal outputs.
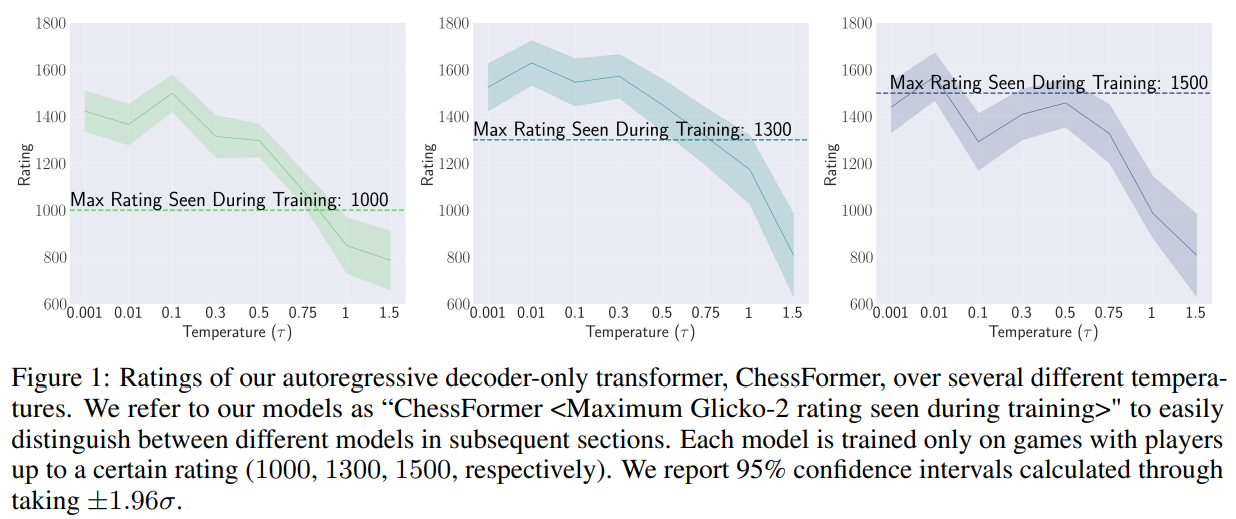
To evaluate the theoretical results on transcendence in chess-playing models, various autoregressive transformer models were trained on a dataset of one billion games from lichess.org. The models operating without direct access to the board state were tested against the Stockfish chess engine under different temperature sampling settings. Results demonstrated that low-temperature sampling significantly improved the model’s play by enhancing its move selection during critical game states. The study found that models trained on more diverse datasets, such as those with lower rating caps, were better at transcending their training limitations, highlighting the importance of dataset diversity for achieving transcendence.
In conclusion, the study introduces transcendence, where generative models trained on expert data outperform the best individual experts. Theoretical analysis indicates that low-temperature sampling achieves transcendence by denoising expert biases and consolidating diverse knowledge, validated through chess model training. The study underscores the importance of dataset diversity for transcendence and suggests future research in other domains like NLP and computer vision to assess generalizability. Ethical considerations in deploying generative models and their broader impact are also highlighted, noting that the study does not imply models can create novel solutions beyond human expert capability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
