AI Video Generation has become increasingly popular in many industries due to its efficacy, cost-effectiveness, and ease of use. However, most state-of-the-art video generators rely on bidirectional models that consider both forward and backward temporal information to create each video part. This approach yields high-quality videos but presents a heavy computational load and is not time-efficient. Therefore, bidirectional models are not ideal for real-world applications. A casual video generation technique has been introduced to address these limitations, which relies solely on previous frames to create the next scene. However, this technique ends up compromising the quality of the video. In order to bridge this gap of high-quality bidirectional model to the efficiency of casual video generation, researchers from MIT and Adobe have devised a groundbreaking model, namely CausVid, for fast-casual video generation.
Conventionally, video generation relies on bidirectional models, which process the entire sequence of the videos to generate each frame. The video quality is high, and little to no manual intervention is required. However, not only does it increase the generation time of the video due to computational intensity, but it also makes handling long videos much more restrictive. Interactive and streaming applications require a more casual approach, as they simply cannot provide future frames for the bidirectional model to analyse. The newly adopted casual video generation only takes into account the past frames to quickly generate the next frame. However, it leads to an inferior-quality video, such as visual artifacts, inconsistencies, or lack of temporal coherence. Existing causal methods have struggled to close the quality gap with bidirectional models.
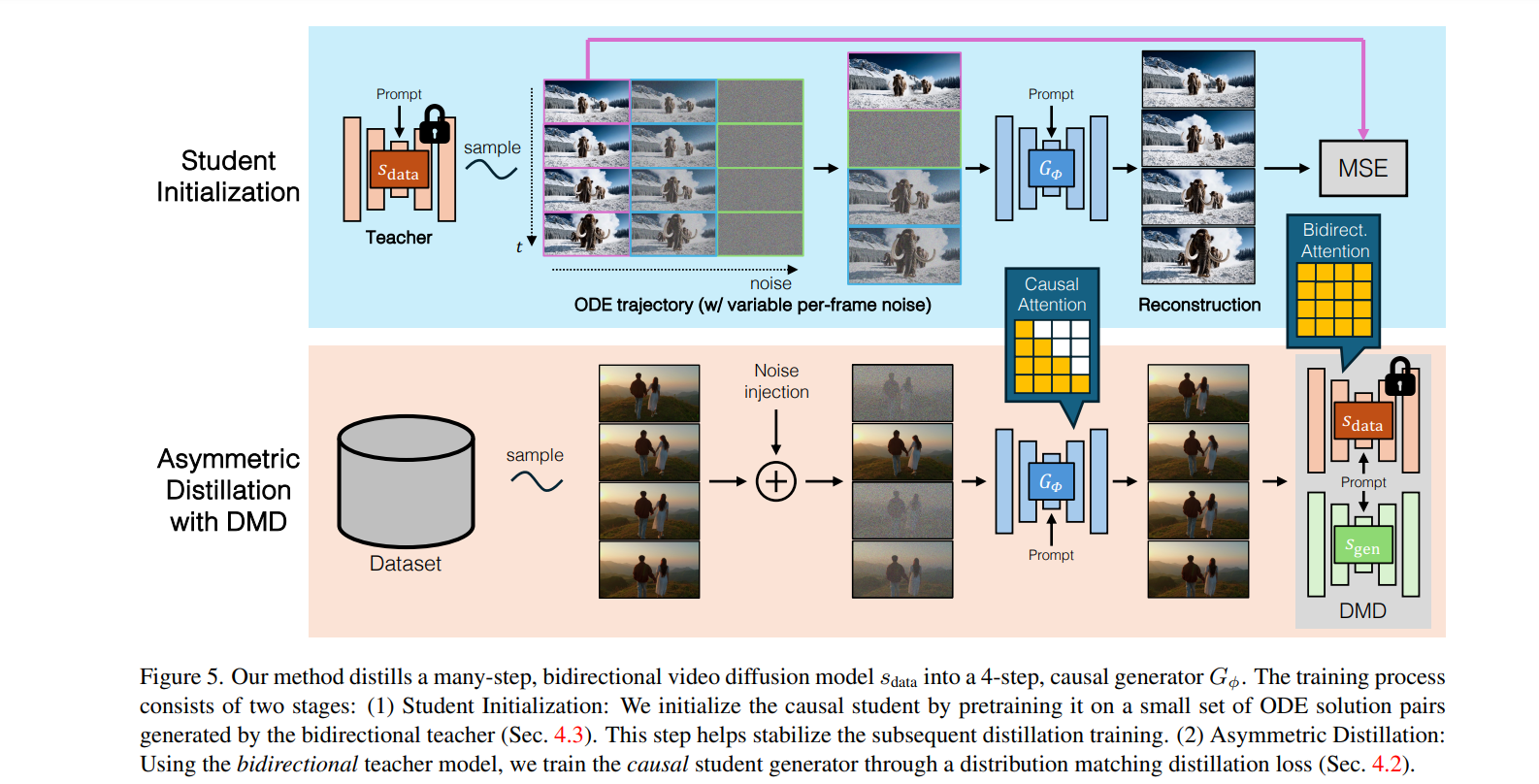
The proposed solution, CausVid, generates subsequent video sequences using the casual method, which depends only on the preceding frames. Here, the KV caching technique is introduced, which enables storing and retrieving essential information from previous frames without the need for actual calculations to speed up the generation process; it reduces the processing time along the video processing pipeline by compressing video frames into lower dimensional representations. The logical connection between each frame is maintained by block-wise causal attention, which focuses on the relationships between consecutive frames within a local context. Within each block of frames, the model uses bidirectional self-attention to analyze all the blocks collectively to ensure consistency and smooth transitions.
The researchers validated their model using multiple datasets, including action recognition and generative benchmarks. The proposed method achieves an improvement in temporal consistency and a reduction in visual artifacts compared to existing causal models. Moreover, the model processes frames faster than bidirectional approaches, with minimal resource usage. In applications like game streaming and VR environments, the model demonstrated seamless integration and superior performance compared to traditional methods.
In summary, the framework of Fast Causal Video Generators bridges the gap between bidirectional and causal models and provides an innovative approach toward real-time video generation. The challenges around temporal coherence and visual quality have been addressed while setting up a foundation that kept the performance intact regarding the usage of video synthesis in interactive settings. This work is proof of task-specific optimization being the way forward for generative models and has demonstrated how proper technique transcends the limitations posed by general-purpose approaches. Such quality and efficiency set a benchmark in this field, opening towards a future where real-time video generation is practical and accessible.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.

Afeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Technology(IIT), Kharagpur. She is passionate about Data Science and fascinated by the role of artificial intelligence in solving real-world problems. She loves discovering new technologies and exploring how they can make everyday tasks easier and more efficient.
