Large language models (LLMs) have gained significant attention due to their potential to enhance various artificial intelligence applications, particularly in natural language processing. When integrated into frameworks like Retrieval-Augmented Generation (RAG), these models aim to refine AI systems’ output by drawing information from external documents rather than relying solely on their internal knowledge base. This approach is crucial in ensuring that AI-generated content remains factually accurate, which is a persistent issue in models not tied to external sources.
A key problem faced in this area is the occurrence of hallucinations in LLMs—where models generate seemingly plausible but factually incorrect information. This becomes especially problematic in tasks requiring high accuracy, such as answering factual questions or assisting in legal and educational fields. Many state-of-the-art LLMs rely heavily on parametric knowledge information learned during training, making them unsuitable for tasks where responses must strictly come from specific documents. To tackle this issue, new methods must be introduced to evaluate and improve the trustworthiness of these models.
Traditional methods focus on evaluating the end results of LLMs within the RAG framework, but few explore the intrinsic trustworthiness of the models themselves. Currently, approaches like prompting techniques align the models’ responses with document-grounded information. However, these methods often fall short, either failing to adapt the models or resulting in overly sensitive outputs that respond inappropriately. Researchers identified the need for a new metric to measure LLM performance and ensure that the models provide grounded, trustworthy responses based solely on retrieved documents.
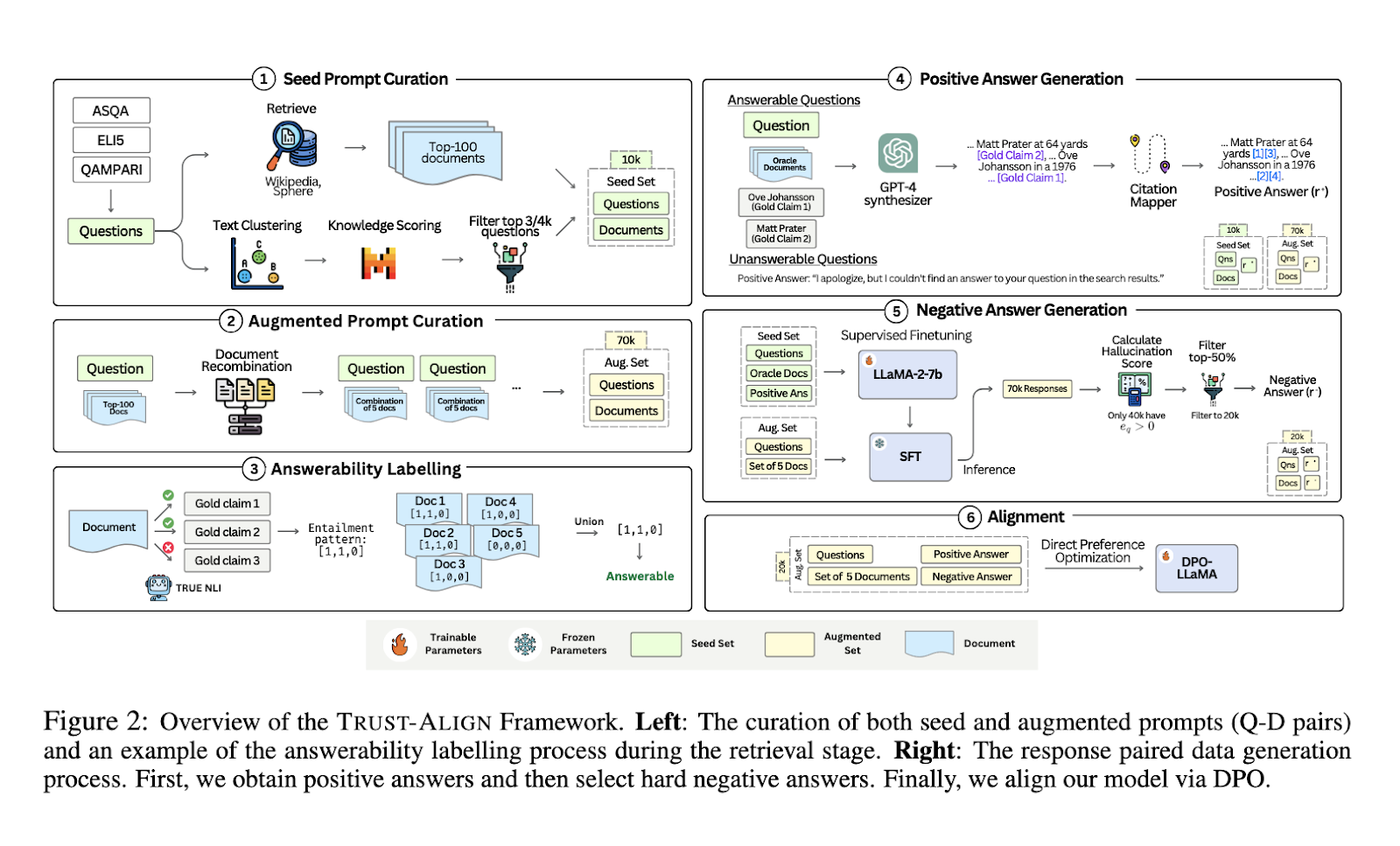
Researchers from the Singapore University of Technology and Design, in collaboration with DSO National Laboratories, introduced a novel framework called “TRUST-ALIGN.” This method focuses on enhancing the trustworthiness of LLMs in RAG tasks by aligning their outputs to provide more accurate, document-supported answers. The researchers also developed a new evaluation metric, TRUST-SCORE, which assesses models based on multiple dimensions, such as their ability to determine whether a question can be answered using the provided documents and their precision in citing relevant sources.
TRUST-ALIGN works by fine-tuning LLMs using a dataset containing 19,000 question-document pairs, each labeled with preferred and unpreferred responses. This dataset was created by synthesizing natural responses from LLMs like GPT-4 and negative responses derived from common hallucinations. The key advantage of this method lies in its ability to directly optimize LLM behavior toward providing grounded refusals when necessary, ensuring that models only answer questions when sufficient information is available. It improves the models’ citation accuracy by guiding them to reference the most relevant portions of the documents, thus preventing over-citation or improper attribution.
Regarding performance, the introduction of TRUST-ALIGN showed substantial improvements across several benchmark datasets. For example, when evaluated on the ASQA dataset, LLaMA-3-8b, aligned with TRUST-ALIGN, achieved a 10.73% increase in the TRUST-SCORE, surpassing models like GPT-4 and Claude-3.5 Sonnet. On the QAMPARI dataset, the method outperformed the baseline models by 29.24%, while the ELI5 dataset showed a performance boost of 14.88%. These figures demonstrate the effectiveness of the TRUST-ALIGN framework in generating more accurate and reliable responses compared to other methods.
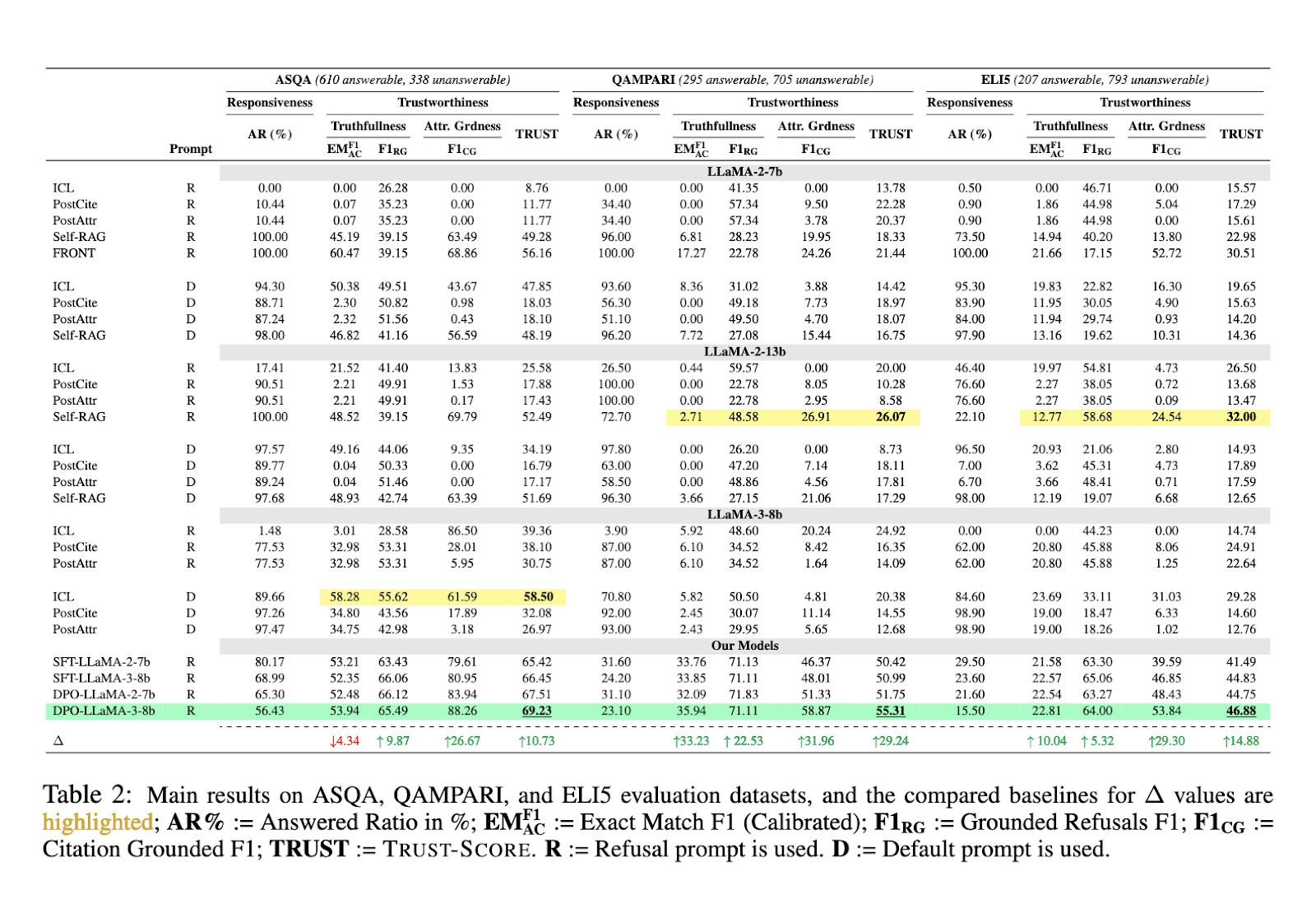
One of the significant improvements brought by TRUST-ALIGN was in the models’ ability to refuse to answer when the available documents were insufficient correctly. On ASQA, the refusal metric improved by 9.87%, while on QAMPARI, it showed an even higher increase of 22.53%. The ability to refuse was further highlighted in ELI5, where the improvement reached 5.32%. These results indicate that the framework enhanced the models’ accuracy and significantly reduced their tendency to over-answer questions without proper justification from the provided documents.
Another noteworthy achievement of TRUST-ALIGN was in improving citation quality. On ASQA, the citation precision scores rose by 26.67%, while on QAMPARI, citation recall increased by 31.96%. The ELI5 dataset also showed an improvement of 29.30%. This improvement in citation groundedness ensures that the models provide well-supported answers, making them more trustworthy for users who rely on fact-based systems.
In conclusion, this research addresses a critical issue in deploying large language models in real-world applications. By developing TRUST-SCORE and the TRUST-ALIGN framework, researchers have created a reliable method to align LLMs toward generating document-grounded responses, minimizing hallucinations, and improving overall trustworthiness. This advancement is particularly significant in fields where accuracy and the ability to provide well-cited information are paramount, paving the way for more reliable AI systems in the future.
Check out the Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
