Graphical User Interface (GUI) agents are crucial in automating interactions within digital environments, similar to how humans operate software using keyboards, mice, or touchscreens. GUI agents can simplify complex processes such as software testing, web automation, and digital assistance by autonomously navigating and manipulating GUI elements. These agents are designed to perceive their surroundings through visual inputs, enabling them to interpret the structure and content of digital interfaces. With advancements in artificial intelligence, researchers aim to make GUI agents more efficient by reducing their dependency on traditional input methods, making them more human-like.
The fundamental problem with existing GUI agents lies in their reliance on text-based representations such as HTML or accessibility trees, which often introduce noise and unnecessary complexity. While effective, these approaches are limited by their dependency on the completeness and accuracy of textual data. For instance, accessibility trees may lack essential elements or annotations, and HTML code may contain irrelevant or redundant information. As a result, these agents need help with latency and computational overhead when navigating through different types of GUIs across platforms like mobile applications, desktop software, and web interfaces.
Some multimodal large language models (MLLMs) have been proposed that combine visual and text-based representations to interpret and interact with GUIs. Despite recent improvements, these models still require significant text-based information, which constrains their generalization ability and hinders performance. Several existing models, such as SeeClick and CogAgent, have shown moderate success. Still, they need to be more robust for practical applications in diverse environments due to their dependence on predefined text-based inputs.
Researchers from Ohio State University and Orby AI introduced a new model called UGround, which eliminates the need for text-based inputs entirely. UGround uses a visual-only grounding approach that operates directly on the visual renderings of the GUI. By solely using visual perception, this model can more accurately replicate human interaction with GUIs, enabling agents to perform pixel-level operations directly on the GUI without relying on any text-based data such as HTML. This advancement significantly enhances the efficiency and robustness of the GUI agents, making them more adaptable and capable of being used in real-world applications.
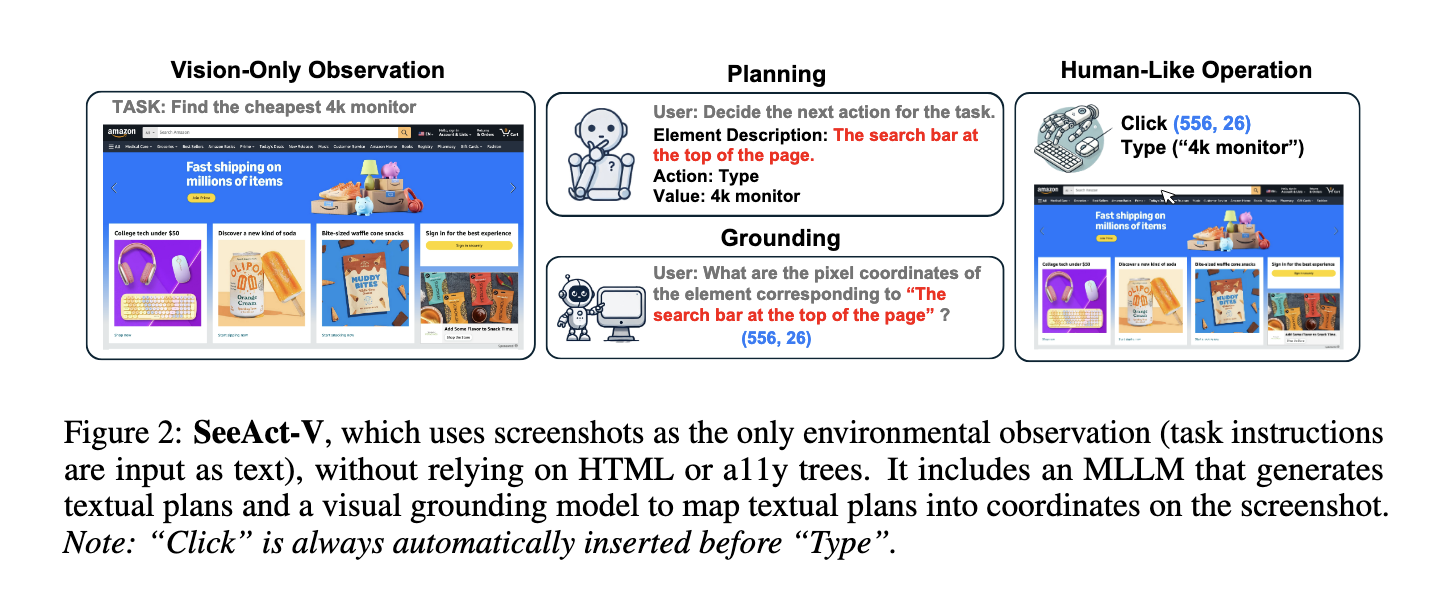
The research team developed UGround by leveraging a simple yet effective methodology, combining web-based synthetic data and slightly adapting the LLaVA architecture. They constructed the largest GUI visual grounding dataset, comprising 10 million GUI elements over 1.3 million screenshots, spanning different GUI layouts and types. The researchers incorporated a data synthesis strategy that allows the model to learn from varied visual representations, making UGround applicable to different platforms, including web, desktop, and mobile environments. This vast dataset helps the model accurately map diverse referring expressions of GUI elements to their coordinates on the screen, facilitating precise visual grounding in real-world applications.
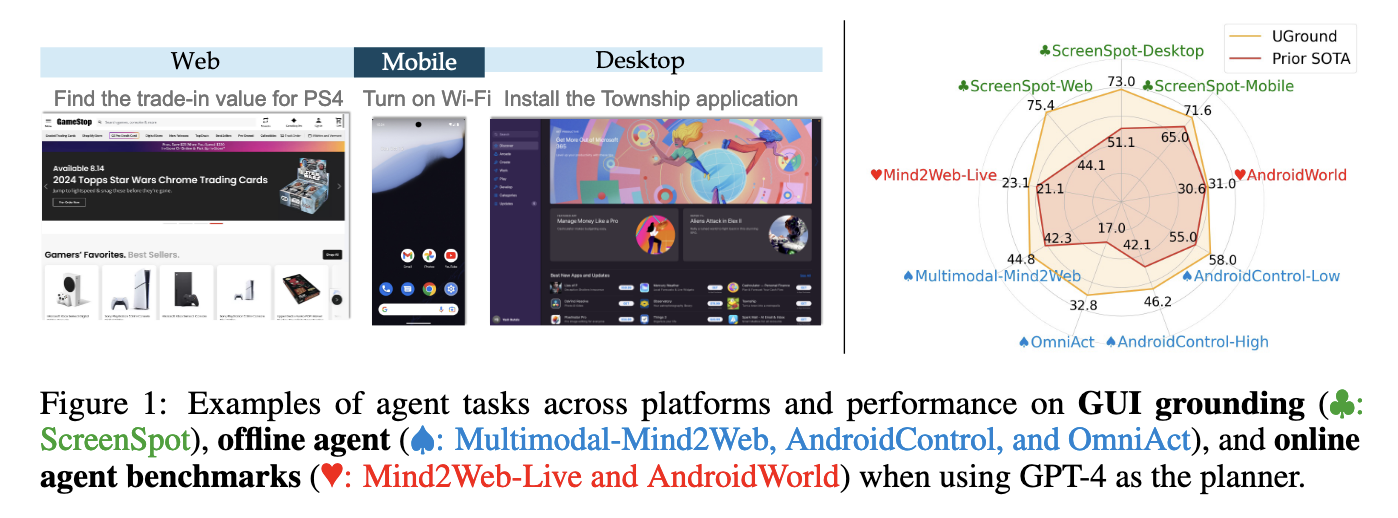
Empirical results showed that UGround significantly outperforms existing models in various benchmark tests. It achieved up to 20% higher accuracy in visual grounding tasks across six benchmarks, covering three categories: grounding, offline agent evaluation, and online agent evaluation. For example, on the ScreenSpot benchmark, which assesses GUI visual grounding across different platforms, UGround achieved an accuracy of 82.8% in mobile environments, 63.6% in desktop environments, and 80.4% in web environments. These results indicate that UGround’s visual-only perception capability allows it to perform comparably or better than models using both visual and text-based inputs.


In addition, GUI agents equipped with UGround demonstrated superior performance compared to state-of-the-art agents that rely on multimodal inputs. For instance, in the agent setting of ScreenSpot, UGround achieved an average performance increase of 29% over the previous models. The model also showed impressive results in AndroidControl and OmniACT benchmarks, which test the agent’s ability to handle mobile and desktop environments, respectively. In AndroidControl, UGround achieved a step accuracy of 52.8% in high-level tasks, surpassing previous models by a considerable margin. Similarly, on the OmniACT benchmark, UGround attained an action score of 32.8, highlighting its efficiency and robustness in diverse GUI tasks.
In conclusion, UGround addresses the primary limitations of existing GUI agents by adopting a human-like visual perception and grounding methodology. Its ability to generalize across multiple platforms and perform pixel-level operations without needing text-based inputs marks a significant advancement in human-computer interaction. This model improves the efficiency and accuracy of GUI agents and sets the foundation for future developments in autonomous GUI navigation and interaction.
Check out the Paper, Code, and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
