Generative Intelligence has remained a hot topic for some time, with the current world witnessing an unprecedented boom in AI-related innovations and research, especially after the introduction of Large Language Models. A significant amount of funding is being allocated to LLM-related research in academia and industry, and it is intended to create the subsequent breakthrough intervention that would disrupt the industry afterward. Upon scrutinizing Large Language Multi Models, we see that the general sentiment persisting today claims that these have successfully addressed the challenges associated with video content, specifically short ones. Consequently, LLMs are moving to address more challenging tasks in multimodal content, including longer videos. However, Is this claim authentic, and have we achieved human par performance with SOTA LLMs for short videos? Vinoground scrutinizes this claim and assesses if we are ready to level up or if LLMs need to revisit their foundations in video comprehension.
Vinoground is a temporal counterfactual LLM evaluation benchmark by researchers from the University of Wisconsin. It consists of 1000 short and natural videos along with their captions. This challenging dataset assesses LLMs’ ability to comprehend videos with dense temporal information. The factor distinguishing VinoGround from its contemporaries is its naturality, with real-life consecutive actions and transformations truly testing and exposing the incapabilities of current LLMs on video frames. There are barely a few benchmarks that replicate the true practical test ground for LLMs, while many benchmarks are temporally sparse and show that LLMs have single-frame biases, and other temporal counterfactuals are unnatural. State-of-the-art proprietary and open-source LLMs exhibited poor performance on Vinoground, indicating they need to achieve reliable video comprehension.
This data is categorized into three major categories: Object, Action, and Viewpoint. Furthermore, there are four minor categories- interaction, cyclical, spatial, and contextual. Models are assessed against each of these categories. Next comes the caption generation, where the authors choose GPT -4 to generate counterfactual captions over costly human annotations. These captions had to have the exact words in different permutations. Video Curation was perhaps the most crucial task, and Vinoground utilized the untrained test and validation part of the VATEX dataset. VATEX’s captions were matched against GPT-generated ones through feature extraction via the FAISS library. If there were no suitable matches, authors looked up YouTube to find a muse for their GPT captions. Finally, the dataset was divided as per the following criterion :
- Object- Videos showed a transformation in the object’s state.
- Action- Set of tasks occurring in different orders to see if the model can catch this swap.
- Viewpoint-changes in the camera angle, perspective, or focus
- Interaction-videos where a human changes their way of interacting with an object
- Cyclical- Videos with procedural temporal activities and dependent activities
- Spatial- Object movements across space
- Contextual- To understand changes in the background or general information of the entire video
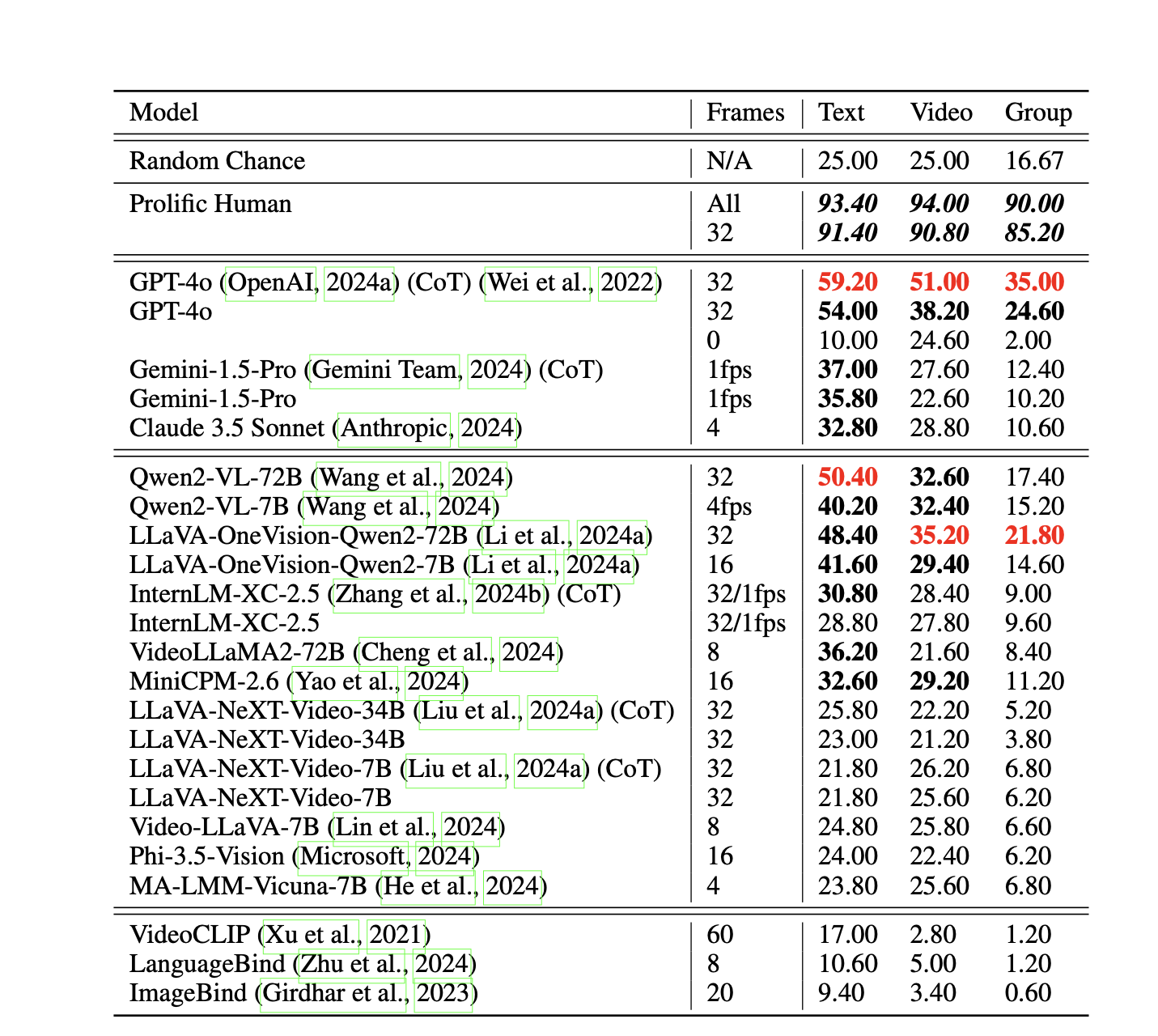
Vinoground exposed the claims of both proprietary and open-sourced models. Clip-based models like video clips and LanguageBind performed even worse than the random chances.GPT 4o performed the best regarding generative models, with 54% on the text score metric. It was performed using Chain of Thought (CoT) prompting on GPT, but there was a tradeoff with group performance. Open-sourced models like LLaVA-OneVision and Qwen2-VL performed parallelly, and their performance didn’t alter after using CoT.
Experts say we need AI that is 1) Accurate and Reliable, 2) Energy Efficient, and 3) Customizable in the same order of priority not otherwise. Developers claim that their LLMs are reliable in performance and at par with humans, but researchers like VinoGround give a reality check for the AI community and LLM developers to ponder over their claims.
Check out the Paper, Project, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.
