Artificial intelligence (AI) has become a transformative technology in many fields, particularly through chatbots in diverse customer service, education, and entertainment applications. These chatbots interact with millions of users daily, generating massive amounts of conversation data. Studying this data presents significant opportunities for understanding user behavior, improving chatbot algorithms, and enhancing the overall interaction experience. However, analyzing such large datasets is a complex task, requiring advanced tools to manage and extract meaningful insights from the overwhelming information efficiently.
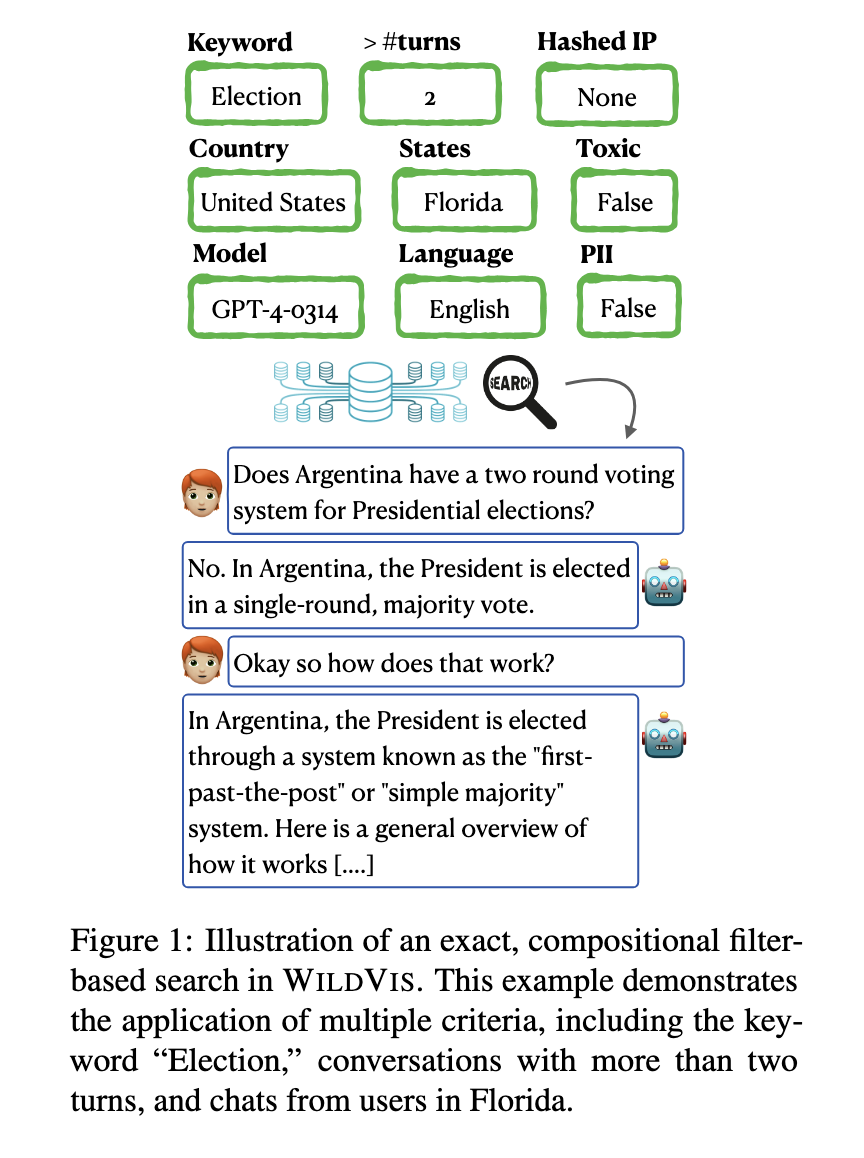
One of the key challenges researchers face in this area is the difficulty of analyzing large-scale chat logs generated by millions of interactions. With such massive datasets, it becomes practically impossible to manually review individual conversations or even identify patterns through conventional methods. Important insights into user behavior, chatbot performance, and potential misuse are likely to remain hidden without appropriate tools. Efficient analysis of this data is essential to uncover trends, improve system designs, and ensure responsible usage of AI technologies.
Currently, tools available for analyzing chatbot logs are limited in their capacity to handle million-scale datasets. Many existing methods focus on smaller-scale data, which is inadequate for the size and complexity of interactions generated by popular chatbots like ChatGPT. While tools such as ConvoKit and others provide some functionality for analyzing dialogue, they are often not scalable or user-friendly enough for analyzing enormous datasets. Furthermore, they lack advanced features like interactive visualizations that allow researchers to explore large datasets easily.
Researchers from the University of Waterloo, Cornell University, Samaya AI, the University of Southern California, the University of Washington, and Nvidia, in a collaborative effort, have developed WILDVIS, a new open-source tool for analyzing large-scale chat logs. The researchers introduced WILDVIS as an interactive visualizer capable of managing millions of chatbot conversations. With WILDVIS, researchers can search, filter, and visualize conversations based on criteria like geographical data, language, toxicity, and model type. This analyzes large-scale chatbot datasets more accessible and efficiently, opening up new opportunities for research into user chatbot interactions.
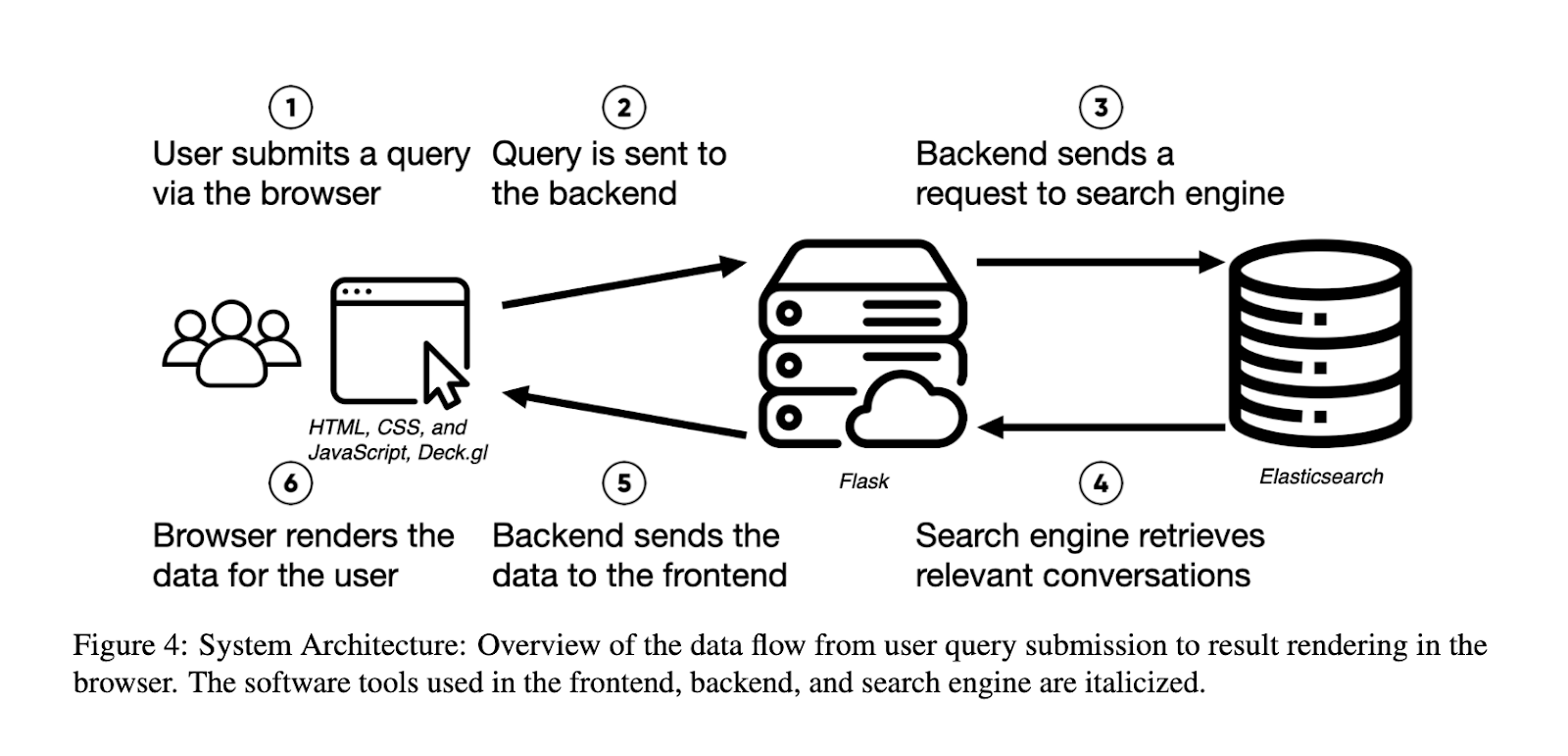
WILDVIS is built using several key technologies that enable its scalability and responsiveness. The tool uses Elasticsearch for scalable search functionality, efficiently retrieving relevant conversations from massive datasets. Further, the system implements precomputed embeddings and caching mechanisms to ensure that searches and visualizations can be performed within seconds, even when dealing with millions of data points. The architecture of WILDVIS includes both frontend and backend optimizations, ensuring smooth user interactions. Users can explore conversations through a filter-based search interface or an embedding-based visualization page, where similar discussions are positioned close together on a 2D map. This approach provides high-level overviews of datasets and the ability to drill down into specific conversation details.
In terms of performance, WILDVIS has demonstrated remarkable efficiency in handling large-scale data. During testing, search queries executed on the filter-based search page had an average execution time of 0.47 seconds, and the embedding visualization page processed queries in an average of 0.43 seconds. The system has been designed to scale effectively, with optimizations such as pagination and embedding precomputation reducing the computational load. WILDVIS can visualize up to 1,500 conversations in a single view while maintaining clarity and responsiveness. In one case study, the tool analyzed millions of conversations from two large datasets—WildChat and LMSYS-Chat-1M—within seconds, highlighting its scalability.
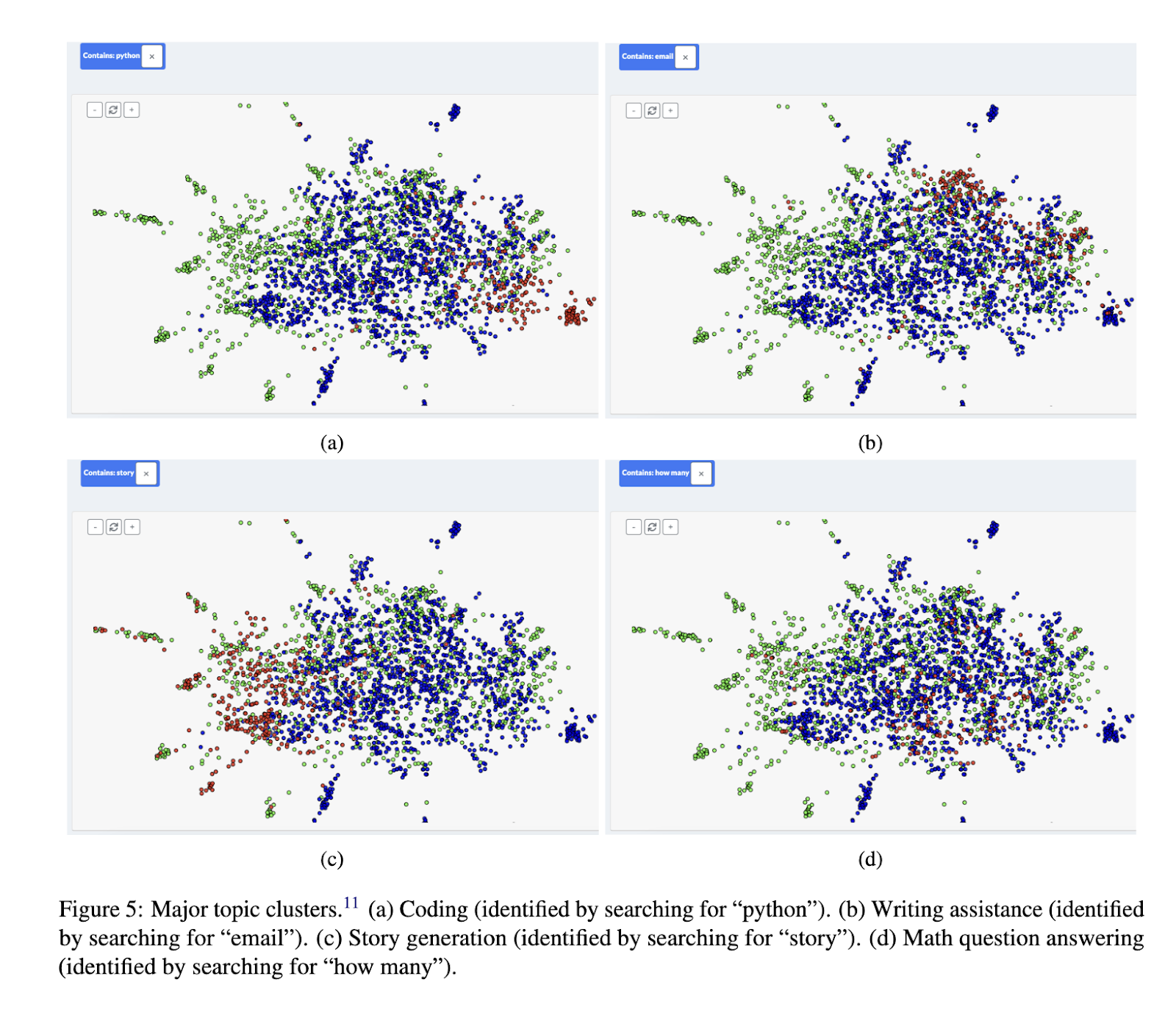
One key finding from WILDVIS’s application in real-world research is its ability to uncover distinct patterns and anomalies in conversation data. For example, when comparing two datasets, researchers found that WildChat had more creative writing-focused conversations, while LMSYS-Chat-1M contained a higher concentration of chemistry-related discussions. This ability to quickly identify and compare topic clusters makes WILDVIS a powerful tool for researchers studying chatbot misuse, user-specific behaviors, and topic distributions across different datasets. By filtering conversations based on specific criteria such as IP address or user location, researchers could also track patterns in individual user interactions, leading to new insights into how chatbots are used across different demographics.
In conclusion, WILDVIS represents a significant advancement in analyzing large-scale chatbot datasets. By introducing powerful search and visualization tools, researchers from institutions such as the University of Waterloo, Cornell University, Nvidia, and the University of Washington have created a system that is not only scalable but also highly responsive. The tool’s ability to uncover patterns, compare datasets, and track user-specific behaviors makes it a valuable resource for researchers looking to deepen their understanding of user chatbot interactions. By addressing the challenges of large-scale data analysis, WILDVIS opens up new avenues for exploring the dynamics of human-AI interaction and improving the performance and accountability of chatbot systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
