
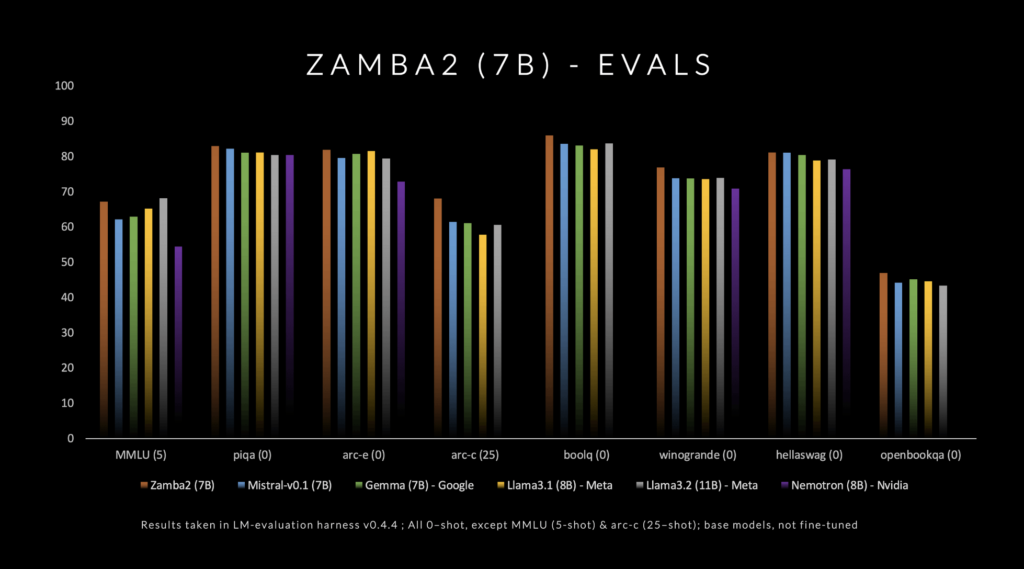
Zyphra has officially released Zamba2-7B, a state-of-the-art small language model that promises unprecedented performance in the 7B parameter range. This model outperforms existing competitors, including Mistral-7B, Google’s Gemma-7B, and Meta’s Llama3-8B, in both quality and speed. Zamba2-7B is specifically designed for environments that require powerful language capabilities but have hardware limitations, such as on-device processing or consumer GPUs. By focusing on efficiency without sacrificing quality, Zyphra is trying to democratize access to advanced AI for a broader audience, from enterprises to individual developers.


The architecture of Zamba2-7B incorporates significant technical innovations that enhance both efficiency and expressivity. Unlike its predecessor, Zamba1, Zamba2-7B uses two shared attention blocks interleaved throughout the network, providing a more sophisticated approach to information flow and cross-sequence dependencies. The Mamba2 blocks form the backbone of the architecture, which allows better parameter utilization compared to traditional transformer models. The use of LoRA (Low-Rank Adaptation) projection on shared MLP blocks is another advancement that helps the model adapt more precisely, thus increasing the versatility of each layer while keeping the model size compact. As a result, Zamba2-7B achieves a 25% reduction in time to the first token and a 20% improvement in tokens processed per second compared to its competitors.
Zamba2-7B is particularly important due to its impressive efficiency and adaptability, which have been validated through rigorous testing. The model was trained on a massive pre-training dataset of three trillion tokens, which includes high-quality and extensively filtered open datasets. Additionally, Zyphra has incorporated an “annealing” pre-training phase, which rapidly decays the learning rate over a curated set of high-quality tokens. This strategy has resulted in superior benchmark performance, as the model comfortably surpasses its competitors in both inference speed and quality. The results indicate that Zamba2-7B is exceptionally suited for tasks involving natural language understanding and generation without the significant computational overhead typically associated with high-quality models.


In conclusion, Zamba2-7B represents a significant step forward in the development of small language models that do not compromise on quality or performance. By blending innovative architectural improvements with efficient training techniques, Zyphra has succeeded in creating a model that is not only accessible but also highly capable of meeting a variety of NLP needs. With the release of Zamba2-7B under an open-source license, Zyphra invites researchers, developers, and enterprises to explore its capabilities, pushing the frontier of what smaller models can achieve. The open availability of Zamba2-7B could well make advanced NLP accessible to a wider community, thereby advancing the field in exciting new ways.
Check out the Details, and Huggingface integration is available here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)


Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.