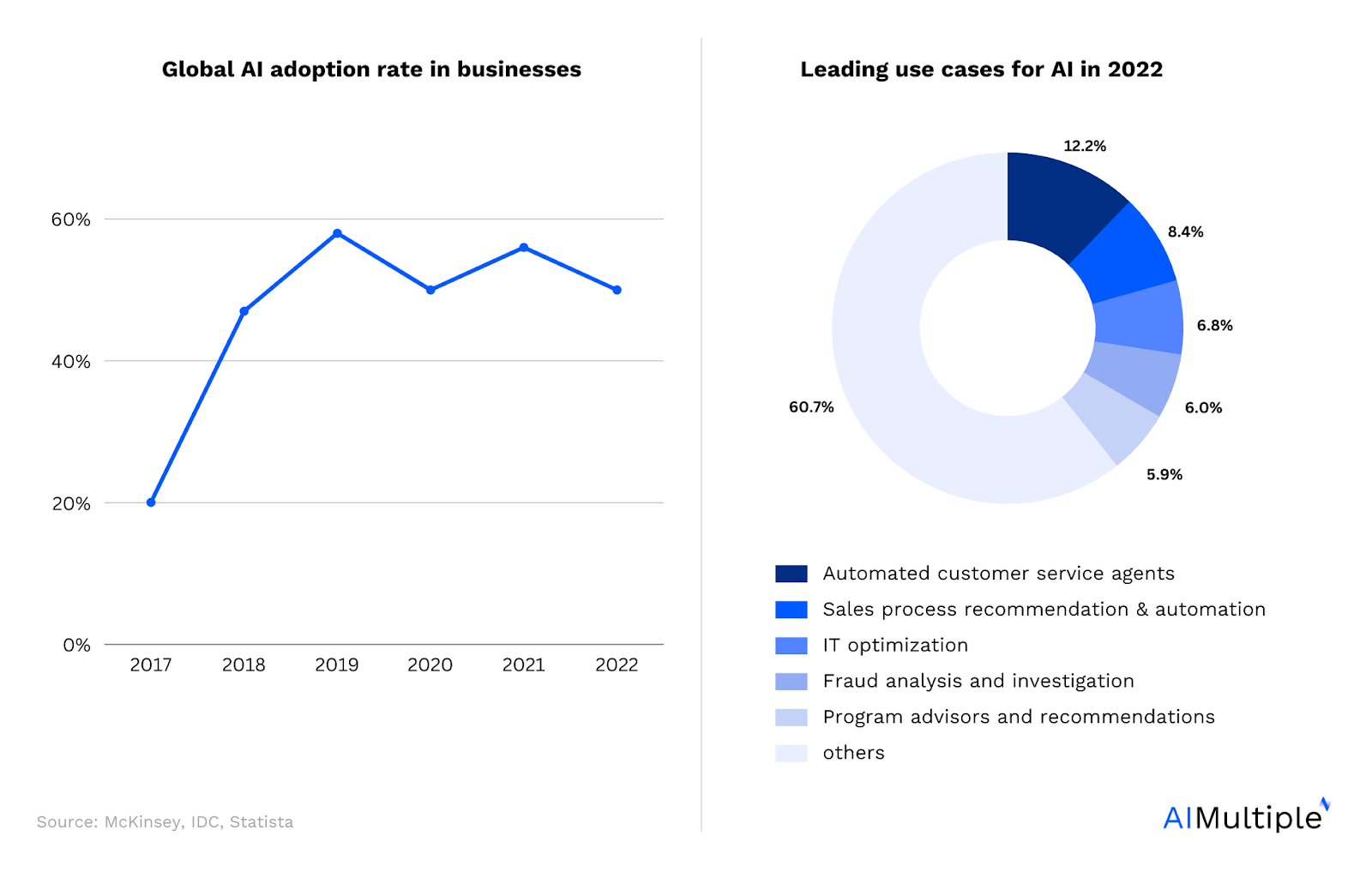
Artificial Intelligence (AI) has become an integral part of business success, and its influence is only increasing (Figure 1). From predictive models that help in healthcare diagnostics to natural language processing (NLP) systems like chatbots and personal assistants, AI applications are endless. Though AI has enormous business potential, 70%1 of AI projects will fail, and executives are looking for ways to ensure the success of their projects.
In this guide, we’ll explore the 7 fundamental steps involved in building an in-house custom AI solution for business leaders planning to initiate AI projects.
Figure 1. Global AI adoption2
1. Defining objectives and requirements
This stage falls under the planning process.
1.1. Determine the scope
Before diving into machine learning algorithms and neural networks, you must first define what you aim to achieve with your AI system. Whether it’s improving customer service through a chatbot or analyzing unstructured data for market research, be clear on your objectives.
You can use this comprehensive library of over 100 AI use cases and applications to learn where to implement AI in your business:
1.2. Resource allocation
Depending on the project’s complexity, you’ll need a varying amount of resources. This involves not just computational resources but also human resources like data scientists and AI developers. Planning ahead ensures smooth development down the road.
2. Gathering data
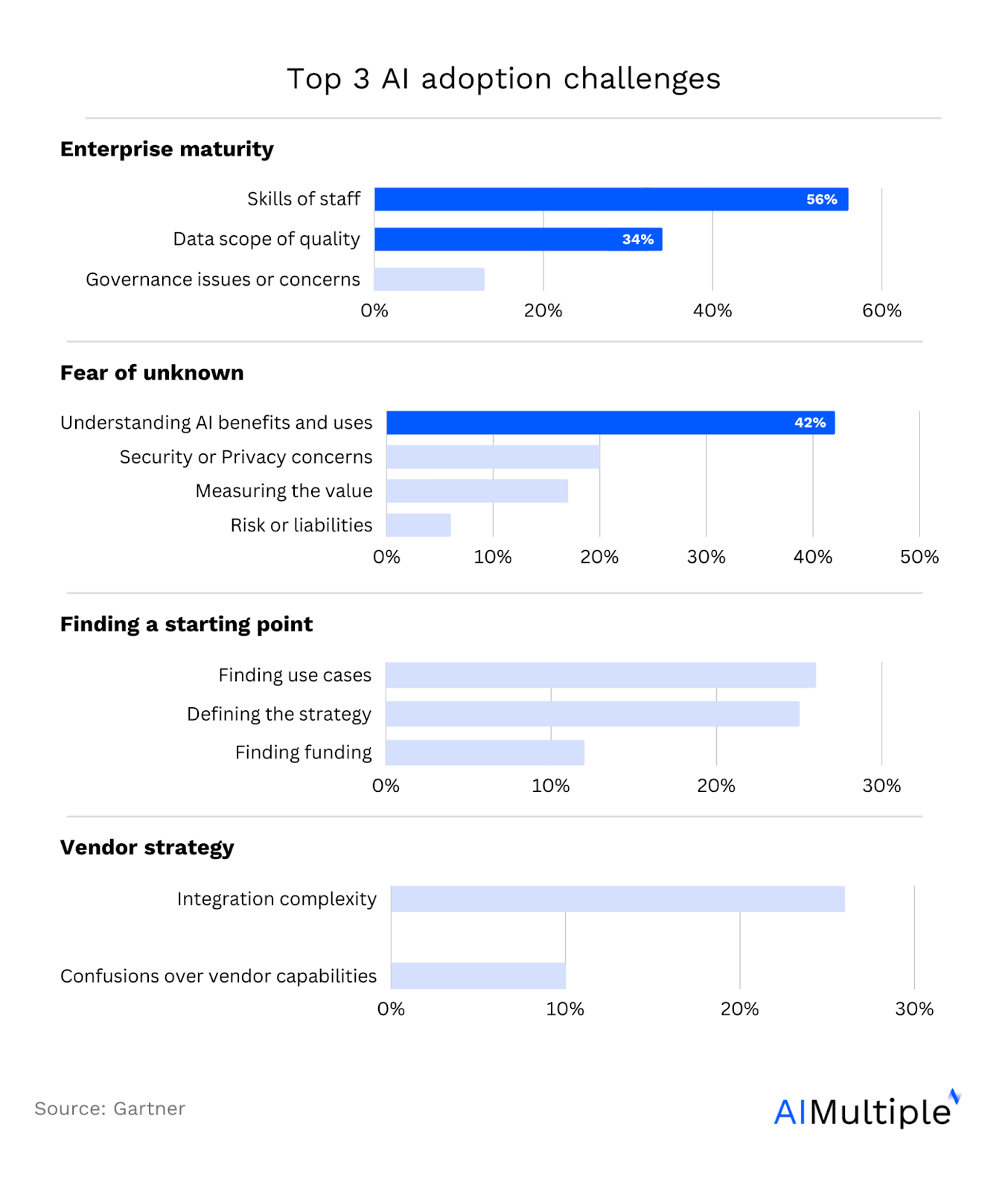
Gathering training data is one of the most important stages of developing an AI model since data acts as fuel for a machine-learning model. Studies show that acquiring relevant and high-quality data is one of the biggest barriers to AI adoption (Figure 3).
Figure 3. Top 3 barriers to AI adoption3
2.1. Understanding data types
Training data is the backbone of any machine learning system. You will generally deal with two types of data:
- Structured Data: Organized data like databases and Excel spreadsheets.
- Unstructured Data: Text, images, audio, video, or any other data that isn’t organized in a pre-defined manner.
2.2. Data sources
Depending on your AI application, relevant data can come from various sources, such as using pre-packaged data, generating or collecting your own data, leveraging crowdsourcing, and automating the data collection process through web scraping tools.
You can use the following data collection methods:

Sponsored
Clickworker offers human-generated training datasets for AI models through a crowdsourcing model. Its global network of over 4.5 million workers offers scalable data and RLHF services to 4 out of 5 tech giants in the U.S. Clickworker also offers:
- Data annotation
- RLHF (Reinforcement learning from human feedback)
You can also check this guide to find the right data collection service for your project.
3. Data preparation and manipulation
This stage comes after the data has been gathered. This usually involves making the dataset more aligned with the scope of the AI project.
3.1. Data quality and cleaning
Low-quality data can hamper model performance. Hence, data cleaning, which involves removing or correcting erroneous data, is an essential step in the process. This stage usually involves data preprocessing, which involves ensuring the quality of the data, while it’s being gathered.
3.2. Transforming raw data
In other words, this stage is called post-processing of the training data. This involves converting raw data into a format suitable for machine learning models. This is where data manipulation techniques come in handy. Data scientists usually employ data analysis tools to convert raw data into relevant features.
3.3. Feature selection
This involves identifying the most relevant variables or features that will help the AI algorithms in pattern recognition or other tasks.
3.4. Data annotation
At this stage, you might also need to use data annotation to make the data machine readable. You can use data annotation tools, or work with a data service provider which offers data annotation services.
Gathering data for developing AI models can be a time-consuming and resource-intensive process; here is an illustration simplifying the entire process:
Figure 3. The process of gathering and generating robust AI training datasets

Read this article to learn more about these 6 steps of gathering relevant AI training data.
4. Model selection and development
4.1. Choosing the right algorithms
Machine learning offers a rich array of algorithms designed to handle various tasks. On one end, you have deep learning algorithms highly suitable for complex functions such as image and speech recognition. These algorithms, often inspired by neural networks, excel in pattern recognition and can process unstructured data effectively. Deep learning models are particularly popular in AI projects related to CV (computer vision) and NLP (natural language processing).
Choosing the right algorithm depends on multiple factors, such as:
- Type of task: Is it classification, regression, or clustering?
- Quality and quantity of data: Do you have a large volume of high-quality data, or are you working with a smaller dataset?
- Computational resources: Do you have the computing power to support more complex algorithms?
- Time constraints: How quickly does the model need to be deployed?
4.2. Using pre-trained models
Pre-trained models can expedite the AI development process. These models have already been trained on comprehensive datasets and can be adapted for similar tasks. For instance, if you’re working on image recognition, using a pre-trained model like VGG or ResNet could save significant training time.
Even though pre-trained models provide a strong foundation, they often require fine-tuning for your specific needs. Training the model on your own dataset can better align its capabilities with your project’s goals, thereby delivering more effective performance. This approach blends the advantages of both custom and pre-trained models.
4.3. Programming languages and tools
The most common programming languages for AI software development are Python, R, and Java. Additionally, deep learning frameworks like TensorFlow and PyTorch are often used for more complex models.
5. Training the model
The training process is one of the most critical phases of the entire development process.
5.1. The training process
Here your AI model learns the ins and outs of the tasks it’s supposed to perform. This involves inputting your cleaned and pre-processed data into the model. As the model sifts through this data, it learns to make predictions based on the information it has received.
For instance, in the case of a machine learning model designed for sentiment analysis, the training process involves exposing the model to various text samples along with their sentiment labels, enabling the model to identify patterns in how words and phrases relate to sentiments.
5.2. Continuous learning
AI models have the ability to evolve and adapt through a method called continuous learning. This is especially important in today’s fast-changing landscape, where data is continually being generated. By regularly updating the model with new data, you ensure that it remains relevant and accurate in its predictions and decisions.
Check out this quick read to learn more about the AI training process.
6. Validation and testing
This is one of the most important stages since it helps identify issues in the AI model and improve them.
6.1. Assessing model performance
After the training process, the next step is to validate the AI model by testing its performance on a new, unseen dataset. Data scientists often use metrics like accuracy, precision, and recall to evaluate model effectiveness.
You can also work with an RLHF (reinforcement learning from human feedback) service provider to improve your model’s performance through a large pool of talent.
6.2. Fine-tuning
If the model doesn’t meet the performance metrics, you might have to go back to the drawing board. This could mean gathering more training data or selecting different machine-learning algorithms.
7. Deployment and maintenance
7.1. Deploying the AI model
Once your model is trained and tested, the final step is to deploy it. Whether it’s a chatbot for customer service or a complex system for data analysis, the AI model must be integrated into existing infrastructures.
7.2. Long-term maintenance
AI projects are not ‘set and forget.’ They require ongoing maintenance to adapt to new data and conditions. This includes monitoring the system’s performance and making necessary updates.
Read this guide to learn more about improving AI models.
Further reading
If you need help finding a vendor or have any questions, feel free to contact us:
Resources
- Sam Ransbotham, et al. (2019). Winning With AI. MITSloan. Accessed: 12/Sep/2023.
- McKinsey, IDC. (2023). Artificial Intelligence: in-depth market analysis 2023. Statista. Accessed: 22/August/2023.
- Laurence Goasduff. (2019). 3 Barriers to AI Adoption. Gartner. Accessed: 22/August/2023.
