Accurately predicting antibody structures is essential for developing monoclonal antibodies, pivotal in immune responses and therapeutic applications. Antibodies have two heavy and two light chains, with the variable regions featuring six CDR loops crucial for binding to antigens. The CDRH3 loop presents the greatest challenge due to its diversity. Traditional experimental methods for determining antibody structures are often slow and costly. Consequently, computational techniques such as IgFold, DeepAb, ABlooper, ABodyBuilder, and newer models like xTrimoPGLMAb are emerging as effective tools for precise antibody structure prediction.
Researchers from Exscientia and the University of Oxford have developed ABodyBuilder3, an advanced model for predicting antibody structures. Building on ABodyBuilder2, this new model enhances the accuracy of predicting CDR loops by integrating language model embeddings. ABodyBuilder3 also improves structure predictions with refined relaxation techniques and introduces a Local Distance Difference Test (pLDDT) to estimate uncertainties more precisely. Key improvements include updates to data curation, sequence representation, and structure refinement processes. These advancements make ABodyBuilder3 a scalable solution for accurately assessing many therapeutic antibody candidates.
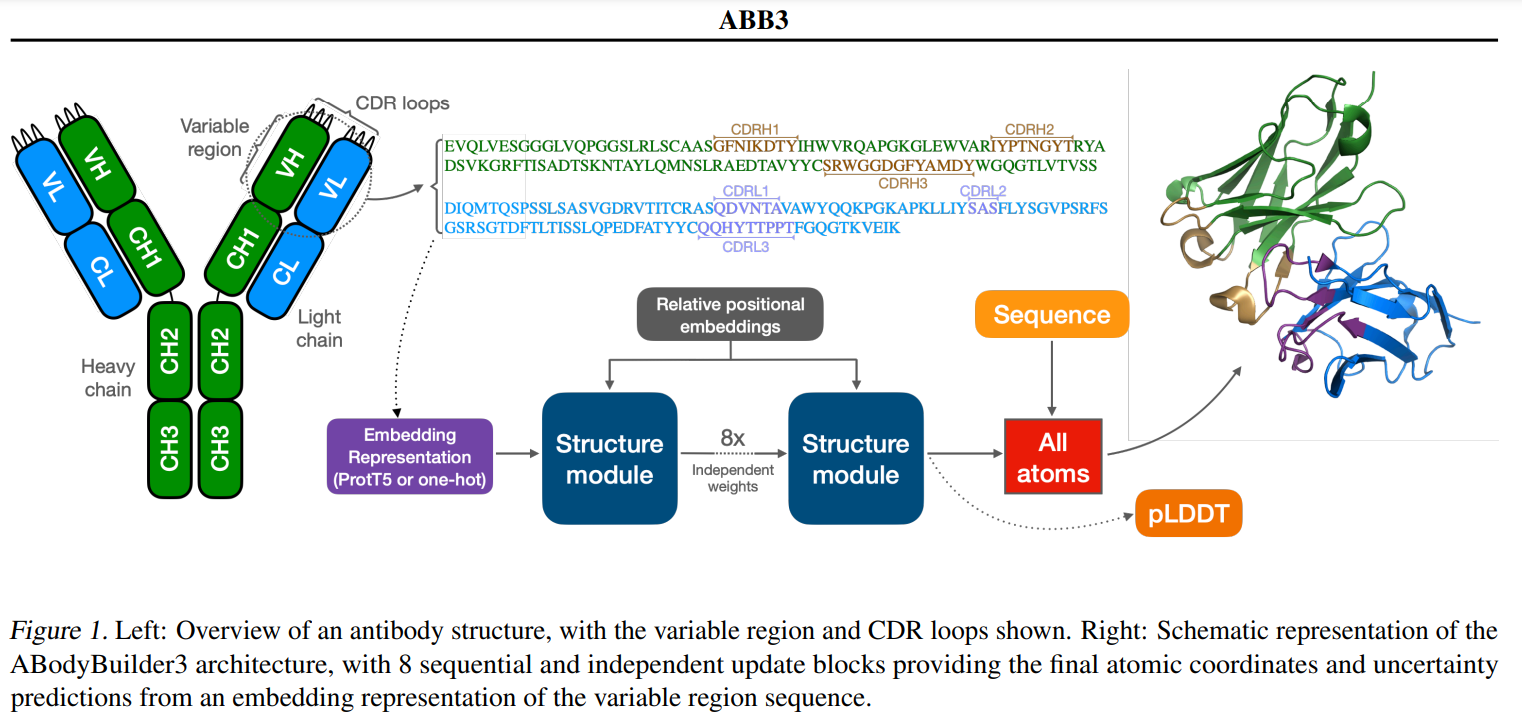
In enhancing antibody structure modeling, researchers developed a more efficient and scalable version of ABodyBuilder2, incorporating vectorization and optimizations from OpenFold. Using mixed precision and bfloat16 for training, they achieved over three times faster performance and efficient memory usage. Training on the Structural Antibody Database (SAbDab), they filtered outliers, ultra-long CDRH3 loops, and low-resolution structures to refine their dataset. They used a large validation and test set focused on human antibodies to improve model robustness. Refinement strategies with OpenMM and YASARA enhanced structural accuracy, particularly in the antibody framework, leading to significant improvements over ABodyBuilder2.
To improve antibody structure modeling, researchers replaced the one-hot encoding in ABodyBuilder2 with embeddings from the ProtT5 language model, which is pretrained on billions of protein sequences. They generated separate embeddings for the heavy and light chains and combined these for the full variable region. While they tested antibody-specific models like IgT5 and IgBert, general protein language models performed better, likely avoiding issues like dataset contamination and overfitting. Using ProtT5, they set a lower initial learning rate and adjusted the learning rate scheduler for stability. This new model, ABodyBuilder3-LM, showed reduced RMSD, especially for CDRH3 and CDRL3 loops.
To enhance uncertainty estimation in antibody structure predictions, ABodyBuilder3 replaces the ensemble-based confidence approach of ABodyBuilder2 with per-residue lDDT-Cα scores, as used in AlphaFold2. This method, which predicts accuracy directly from a single model, significantly reduces computational costs. The pLDDT score is calculated by projecting residue-level predictions into bins via a neural network and then comparing them to ground truth structures. This approach improves the correlation between predicted uncertainty and RMSD, especially with ProtT5 embeddings. The model’s pLDDT scores effectively predict the accuracy of CDR regions, with high scores indicating lower RMSD in key areas like CDRH3.
In conclusion, ABodyBuilder3 is an advanced antibody structure prediction model building on ABodyBuilder2, with key enhancements for improved scalability and accuracy. The model achieves better performance by optimizing hardware usage and refining data processing and structure prediction methods. Incorporating language model embeddings, particularly for the CDRH3 region, and using pLDDT scores for uncertainty estimation replace the need for computationally intensive ensemble models. Future directions could explore self-distillation techniques and pre-training on synthetic datasets to enhance prediction accuracy. Additionally, combining pLDDT with ensemble approaches might improve results despite higher computational demands.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
