The evaluation of LLMs in medical tasks has traditionally relied on multiple-choice question benchmarks. However, these benchmarks are limited in scope, often yielding saturated results with repeated high performance from LLMs, and do not accurately reflect real-world clinical scenarios. Clinical reasoning, the cognitive process physicians use to analyze and synthesize medical data for diagnosis and treatment, is a more meaningful benchmark for assessing model performance. Recent LLMs have demonstrated the potential to outperform clinicians in routine and complex diagnostic tasks, surpassing earlier AI-based diagnostic tools that utilized regression models, Bayesian approaches, and rule-based systems.
Advances in LLMs, including foundation models, have significantly outperformed medical professionals in diagnostic benchmarks, with strategies such as CoT prompting further enhancing their reasoning abilities. OpenAI’s o1-preview model, introduced in September 2024, integrates a native CoT mechanism, enabling more deliberate reasoning during complex problem-solving tasks. This model has outperformed GPT-4 in addressing intricate challenges like informatics and medicine. Despite these advancements, multiple-choice benchmarks fail to capture the complexity of clinical decision-making, as they often enable models to leverage semantic patterns rather than genuine reasoning. Real-world clinical practice demands dynamic, multi-step reasoning, where models must continuously process and integrate diverse data sources, refine differential diagnoses, and make critical decisions under uncertainty.
Researchers from leading institutions, including Beth Israel Deaconess Medical Center, Stanford University, and Harvard Medical School, conducted a study to evaluate OpenAI’s o1-preview model, designed to enhance reasoning through chain-of-thought processes. The model was tested on five tasks: differential diagnosis generation, reasoning explanation, triage diagnosis, probabilistic reasoning, and management reasoning. Expert physicians assessed the model’s outputs using validated metrics and compared them to prior LLMs and human benchmarks. Results showed significant improvements in diagnostic and management reasoning but no advancements in probabilistic reasoning or triage. The study underscores the need for robust benchmarks and real-world trials to evaluate LLM capabilities in clinical settings.
The study evaluated OpenAI’s o1-preview model using diverse medical diagnostic cases, including NEJM Clinicopathologic Conference (CPC) cases, NEJM Healer cases, Grey Matters management cases, landmark diagnostic cases, and probabilistic reasoning tasks. Outcomes focused on differential diagnosis quality, testing plans, clinical reasoning documentation, and identifying critical diagnoses. Physicians assessed scores using validated metrics like Bond Scores, R-IDEA, and normalized rubrics. The model’s performance was compared to historical GPT-4 controls, human benchmarks, and augmented resources. Statistical analyses, including McNemar’s test and mixed-effects models, were conducted in R. Results highlighted o1-preview’s strengths in reasoning but identified areas like probabilistic reasoning needing improvement.
The study evaluated o1-preview’s diagnostic capabilities using New England Journal of Medicine (NEJM) cases and benchmarked it against GPT-4 and physicians. o1-preview correctly included the diagnosis in 78.3% of NEJM cases, outperforming GPT-4 (88.6% vs. 72.9%). It achieved high test-selection accuracy (87.5%) and scored perfectly on clinical reasoning (R-IDEA) for 78/80 NEJM Healer cases, surpassing GPT-4 and physicians. In management vignettes, o1-preview outperformed GPT-4 and physicians by over 40%. It achieved a median score of 97% for landmark diagnostic cases, comparable to GPT-4 but higher than physicians. Probabilistic reasoning was performed similarly to GPT -4, with better accuracy in coronary stress tests.
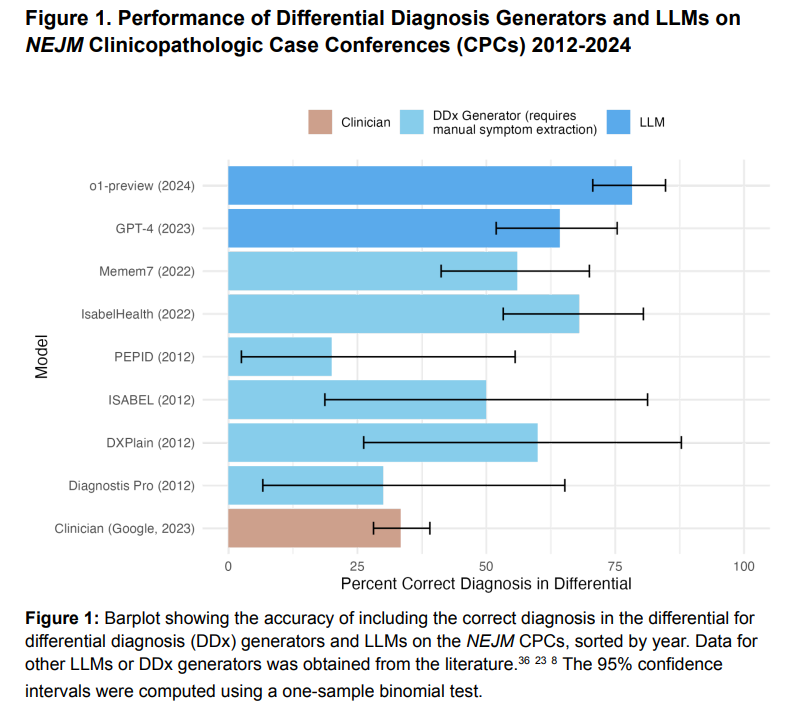
In conclusion, The o1-preview model demonstrated superior performance in medical reasoning across five experiments, surpassing GPT-4 and human baselines in tasks like differential diagnosis, diagnostic reasoning, and management decisions. However, it showed no significant improvement over GPT-4 in probabilistic reasoning or critical diagnosis identification. These highlight the potential of LLMs in clinical decision support, though real-world trials are necessary to validate their integration into patient care. Current benchmarks, like NEJM CPCs, are nearing saturation, prompting the need for more realistic, challenging evaluations. Limitations include verbosity, lack of human-computer interaction studies, and a focus on internal medicine, underscoring the need for broader assessments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
