Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP), particularly in Question Answering (QA). However, hallucination remains a significant obstacle as LLMs may generate factually inaccurate or ungrounded responses. Studies reveal that even state-of-the-art models like GPT-4 struggle with accurately answering questions involving changing facts or less popular entities. Overcoming hallucinations is crucial for developing reliable QA systems. Retrieval-Augmented Generation (RAG) has emerged as a promising approach to address LLMs’ knowledge deficiencies, but it faces challenges like selecting relevant information, reducing latency, and synthesizing information for complex queries.
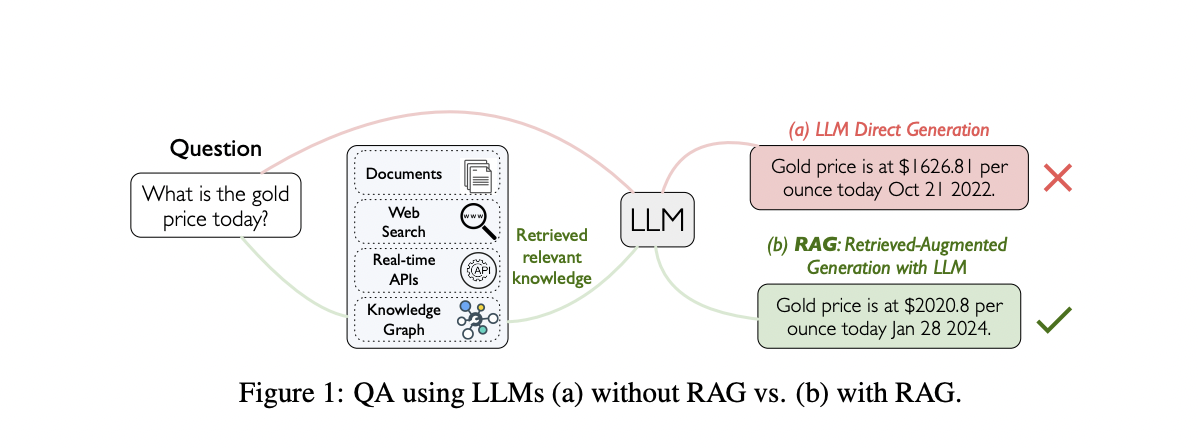
Researchers from Meta Reality Labs, FAIR, Meta, HKUST, and HKUST (GZ) proposed a benchmark called CRAG (Comprehensive benchmark for RAG), which aims to incorporate five critical features: realism, richness, insightfulness, reliability, and longevity. It contains 4,409 diverse QA pairs from five domains, including simple fact-based and seven types of complex questions. CRAG covers varying entity popularity and temporal spans to enable insights. The questions are manually verified and paraphrased for realism and reliability. Also, CRAG provides mock APIs simulating retrieval from web pages (via Brave Search API) and mock knowledge graphs with 2.6 million entities, reflecting realistic noise. The benchmark offers three tasks to evaluate the web retrieval, structured querying, and summarisation capabilities of RAG solutions.

A RAG QA system involves three tasks designed to evaluate the different capabilities of the systems. All tasks share the same set of (question, answer) pairs but differ in the external data accessible for retrieval to augment answer generation. Task 1 (Retrieval Summarization) provides up to five potentially relevant web pages per question to test the answer generation capability. Task 2 (KG and Web Retrieval Augmentation) further provides mock APIs to access structured data from knowledge graphs (KGs), examining the system’s ability to query structured sources and synthesize information. Task 3 is similar to Task 2, but provides 50 web pages instead of 5 as retrieval candidates, testing the system’s ability to rank and utilize a larger set of potentially noisy but more comprehensive information.
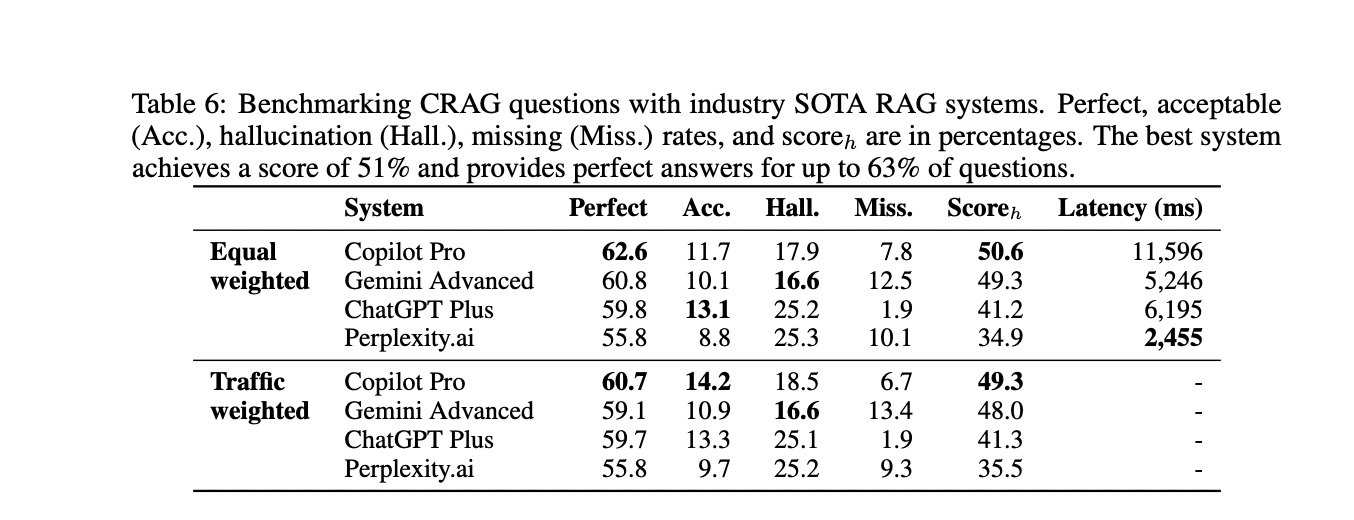
The results and comparisons demonstrate the effectiveness of the proposed CRAG benchmark. While advanced language models like GPT-4 achieve only around 34% accuracy on CRAG, incorporating straightforward RAG improves accuracy to 44%. However, even state-of-the-art industry RAG solutions answer only 63% of questions without hallucination, struggling with facts of higher dynamism, lower popularity, or greater complexity. These evaluations highlight that CRAG has an appropriate level of difficulty and enables insights from its diverse data. The evaluations also underscore the research gaps towards developing fully trustworthy question-answering systems, making CRAG a valuable benchmark for driving further progress in this field.
In this study, the researchers introduce CRAG, a comprehensive benchmark that aims to propel research in RAG for question-answering systems. Through rigorous empirical evaluations, CRAG exposes shortcomings in existing RAG solutions and offers valuable insights for future improvements. The benchmark’s creators plan to continuously enhance and expand CRAG to include multi-lingual questions, multi-modal inputs, multi-turn conversations, and more. This ongoing development ensures CRAG remains at the vanguard of driving RAG research, adapting to emerging challenges, and evolving to address new research needs in this rapidly progressing field. The benchmark provides a robust foundation for advancing reliable, grounded language generation capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
