Natural Language to SQL (NL2SQL) technology has emerged as a transformative aspect of natural language processing (NLP), enabling users to convert human language queries into Structured Query Language (SQL) statements. This development has made it easier for individuals who need more technical expertise to interact with complex databases and retrieve valuable insights. By bridging the gap between database systems and natural language, NL2SQL has opened doors for more intuitive data exploration, particularly in large repositories across various industries, enhancing efficiency and decision-making capabilities.
A significant problem in NL2SQL lies in the trade-off between query accuracy and adaptability. Many methods fail to generate SQL queries that are both precise and versatile across diverse databases. Some rely heavily on large language models (LLMs) optimized through prompt engineering, which generates multiple outputs to select the best query. However, this approach increases computational load and limits real-time applications. On the other hand, supervised fine-tuning (SFT) provides targeted SQL generation but needs help with cross-domain applications and more complex database operations, leaving a gap for innovative frameworks.
Researchers have previously employed diverse methods to address NL2SQL challenges. Prompt engineering focuses on optimizing inputs to generate SQL outputs with tools like GPT-4 or Claude 3.5 Sonnet, but this often results in inference inefficiency. SFT fine-tunes smaller models for specific tasks, yielding controllable results but limited query diversity. Hybrid methods like ExSL and Granite-34B-Code improve results through advanced training but face barriers in multi-database adaptability. These existing approaches emphasize the need for solutions that combine precision, adaptability, and diversity in SQL query generation.
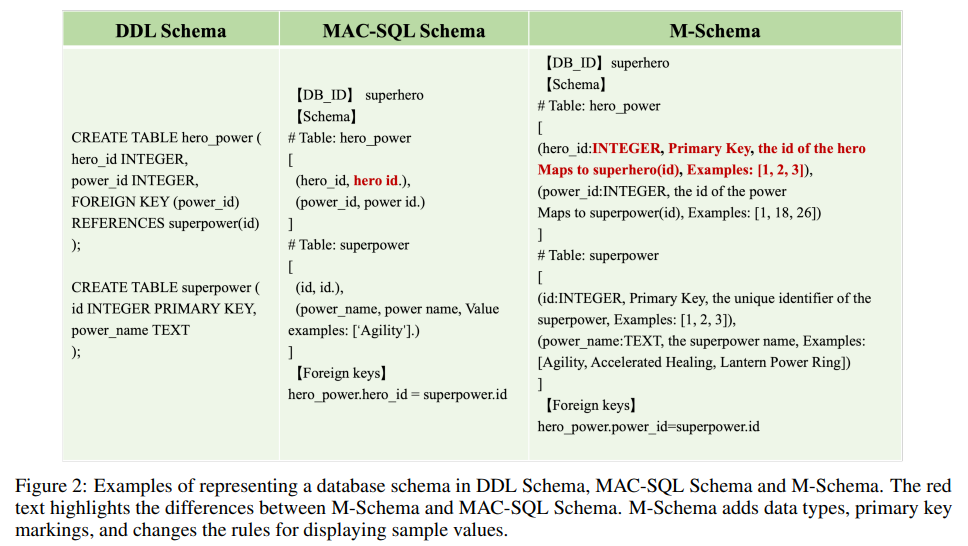
Researchers from Alibaba Group introduced XiYan-SQL, a groundbreaking NL2SQL framework. It integrates multi-generator ensemble strategies and merges the strengths of prompt engineering and SFT. A critical innovation within XiYan-SQL is M-Schema, a semi-structured schema representation method that enhances the system’s understanding of hierarchical database structures. This representation includes key details such as data types, primary keys, and example values, improving the system’s capacity to generate accurate and contextually appropriate SQL queries. This approach allows XiYan-SQL to produce high-quality SQL candidates while optimizing resource utilization.
XiYan-SQL employs a three-stage process to generate and refine SQL queries. First, schema linking identifies relevant database elements, reducing extraneous information and focusing on key structures. The system then generates SQL candidates using ICL and SFT-based generators. This ensures diversity in syntax and adaptability to complex queries. Each generated SQL is refined using a correction model to eliminate logical or syntactical errors. Finally, a selection model, fine-tuned to distinguish subtle differences among candidates, selects the best query. XiYan-SQL surpasses traditional methods by integrating these steps into a cohesive and efficient pipeline.

The framework’s performance has been validated through rigorous testing across diverse benchmarks. XiYan-SQL achieved 89.65% execution accuracy on the Spider test set, surpassing previous leading models by a significant margin. It gained 69.86% on SQL-Eval, outperforming SQL-Coder-8B by over eight percentage points. It demonstrated exceptional adaptability for non-relational datasets, securing 41.20% accuracy on NL2GQL, the highest among all tested models. XiYan-SQL scored a competitive 72.23% in the challenging Bird development benchmark, closely rivaling the top-performing method, which achieved 73.14%. These results highlight XiYan-SQL’s versatility and accuracy in diverse scenarios.
Key takeaways from the research include the following:
- Innovative Schema Representation: The introduction of M-Schema significantly enhances database comprehension by including hierarchical structures, data types, and primary keys. This approach reduces redundancy and improves query accuracy.
- Advanced Candidate Generation: XiYan-SQL uses fine-tuned and ICL-based generators to produce diverse SQL candidates. A multi-task training approach enhances query quality across multiple syntactic styles.
- Robust Error Correction and Selection: The framework employs an SQL refiner to optimize queries and a selection model to ensure the best candidate is chosen. This method replaces less efficient self-consistency strategies.
- Proven Versatility: Testing across benchmarks like Spider, Bird, SQL-Eval, and NL2GQL demonstrates XiYan-SQL’s ability to adapt to relational and non-relational databases.
- State-of-the-Art Performance: XiYan-SQL consistently outperforms leading models, achieving remarkable scores such as 89.65% on Spider and 41.20% on NL2GQL, setting new standards in NL2SQL frameworks.


In conclusion, XiYan-SQL addresses the persistent challenges in NL2SQL tasks by combining advanced schema representation, diverse SQL generation techniques, and precise query selection mechanisms. It achieves a balanced approach to accuracy and adaptability, outperforming traditional frameworks across multiple benchmarks. The research underscores the importance of innovation in NL2SQL systems and paves the way for the broader adoption of intuitive database interaction tools. XiYan-SQL exemplifies how strategic integration of technologies can redefine complex query systems, providing a robust foundation for future advancements in data accessibility.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
