
FIGS (Fast Interpretable Greedy-tree Sums): A method for building interpretable models by simultaneously growing an ensemble of decision trees in competition with one another.
Recent machine-learning advances have led to increasingly complex predictive models, often at the cost of interpretability. We often need interpretability, particularly in high-stakes applications such as in clinical decision-making; interpretable models help with all kinds of things, such as identifying errors, leveraging domain knowledge, and making speedy predictions.
In this blog post we’ll cover FIGS, a new method for fitting an interpretable model that takes the form of a sum of trees. Real-world experiments and theoretical results show that FIGS can effectively adapt to a wide range of structure in data, achieving state-of-the-art performance in several settings, all without sacrificing interpretability.
How does FIGS work?
Intuitively, FIGS works by extending CART, a typical greedy algorithm for growing a decision tree, to consider growing a sum of trees simultaneously (see Fig 1). At each iteration, FIGS may grow any existing tree it has already started or start a new tree; it greedily selects whichever rule reduces the total unexplained variance (or an alternative splitting criterion) the most. To keep the trees in sync with one another, each tree is made to predict the residuals remaining after summing the predictions of all other trees (see the paper for more details).
FIGS is intuitively similar to ensemble approaches such as gradient boosting / random forest, but importantly since all trees are grown to compete with each other the model can adapt more to the underlying structure in the data. The number of trees and size/shape of each tree emerge automatically from the data rather than being manually specified.

Fig 1. High-level intuition for how FIGS fits a model.
An example using FIGS
Using FIGS is extremely simple. It is easily installable through the imodels package (pip install imodels) and then can be used in the same way as standard scikit-learn models: simply import a classifier or regressor and use the fit and predict methods. Here’s a full example of using it on a sample clinical dataset in which the target is risk of cervical spine injury (CSI).
from imodels import FIGSClassifier, get_clean_dataset
from sklearn.model_selection import train_test_split
# prepare data (in this a sample clinical dataset)
X, y, feat_names = get_clean_dataset('csi_pecarn_pred')
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
# fit the model
model = FIGSClassifier(max_rules=4) # initialize a model
model.fit(X_train, y_train) # fit model
preds = model.predict(X_test) # discrete predictions: shape is (n_test, 1)
preds_proba = model.predict_proba(X_test) # predicted probabilities: shape is (n_test, n_classes)
# visualize the model
model.plot(feature_names=feat_names, filename='out.svg', dpi=300)
This results in a simple model – it contains only 4 splits (since we specified that the model should have no more than 4 splits (max_rules=4). Predictions are made by dropping a sample down every tree, and summing the risk adjustment values obtained from the resulting leaves of each tree. This model is extremely interpretable, as a physician can now (i) easily make predictions using the 4 relevant features and (ii) vet the model to ensure it matches their domain expertise. Note that this model is just for illustration purposes, and achieves ~84\% accuracy.

Fig 2. Simple model learned by FIGS for predicting risk of cervical spinal injury.
If we want a more flexible model, we can also remove the constraint on the number of rules (changing the code to model = FIGSClassifier()), resulting in a larger model (see Fig 3). Note that the number of trees and how balanced they are emerges from the structure of the data – only the total number of rules may be specified.

Fig 3. Slightly larger model learned by FIGS for predicting risk of cervical spinal injury.
How well does FIGS perform?
In many cases when interpretability is desired, such as clinical-decision-rule modeling, FIGS is able to achieve state-of-the-art performance. For example, Fig 4 shows different datasets where FIGS achieves excellent performance, particularly when limited to using very few total splits.
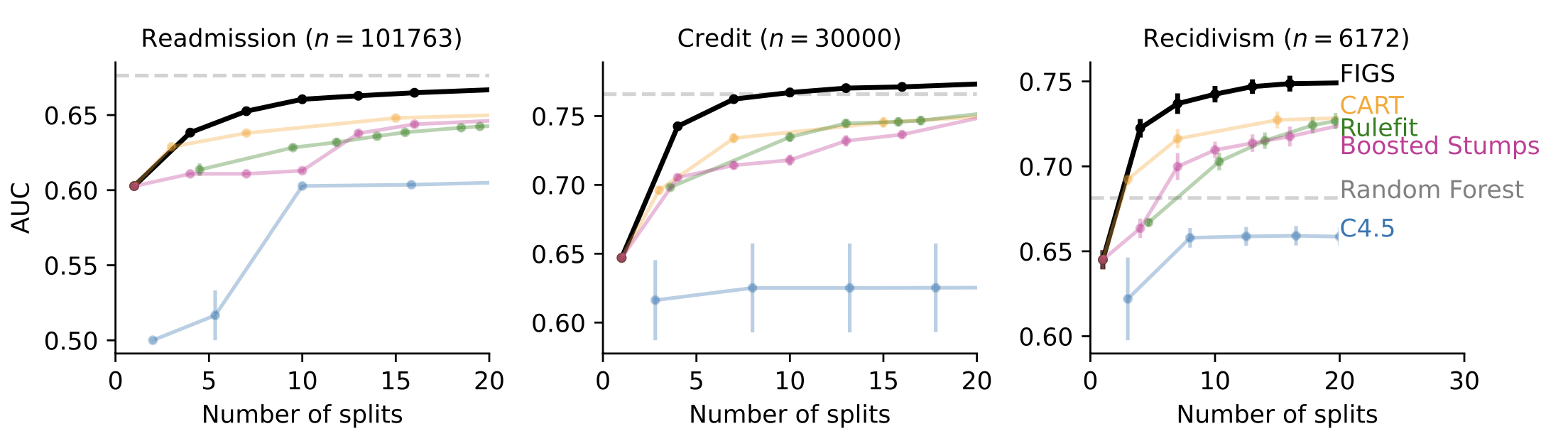
Fig 4. FIGS predicts well with very few splits.
Why does FIGS perform well?
FIGS is motivated by the observation that single decision trees often have splits that are repeated in different branches, which may occur when there is additive structure in the data. Having multiple trees helps to avoid this by disentangling the additive components into separate trees.
Conclusion
Overall, interpretable modeling offers an alternative to common black-box modeling, and in many cases can offer massive improvements in terms of efficiency and transparency without suffering from a loss in performance.
This post is based on two papers: FIGS and G-FIGS – all code is available through the imodels package. This is joint work with Keyan Nasseri, Abhineet Agarwal, James Duncan, Omer Ronen, and Aaron Kornblith.
