The advent of large language models (LLMs) like GPT-4 has sparked excitement around enhancing them with multimodal capabilities to understand visual data alongside text. However, previous efforts to create powerful multimodal LLMs have faced challenges in scaling up efficiently while maintaining performance. To mitigate these issues, the researchers took inspiration from the mixture-of-experts (MoE) architecture, widely used to scale up LLMs by replacing dense layers with sparse expert modules.
In the MoE approach, instead of passing inputs through a single large model, there are many smaller expert sub-models that each specialize on a subset of the data. A routing network determines which expert(s) should process each input example. It allows scaling up total model capacity in a more parameter-efficient way.

In their approach (shown in Figure 2), CuMo, the researchers integrated sparse MoE blocks into the vision encoder and the vision-language connector of a multimodal LLM. This allows different expert modules to process different parts of the visual and text inputs in parallel rather than relying on a monolithic model to analyze everything.
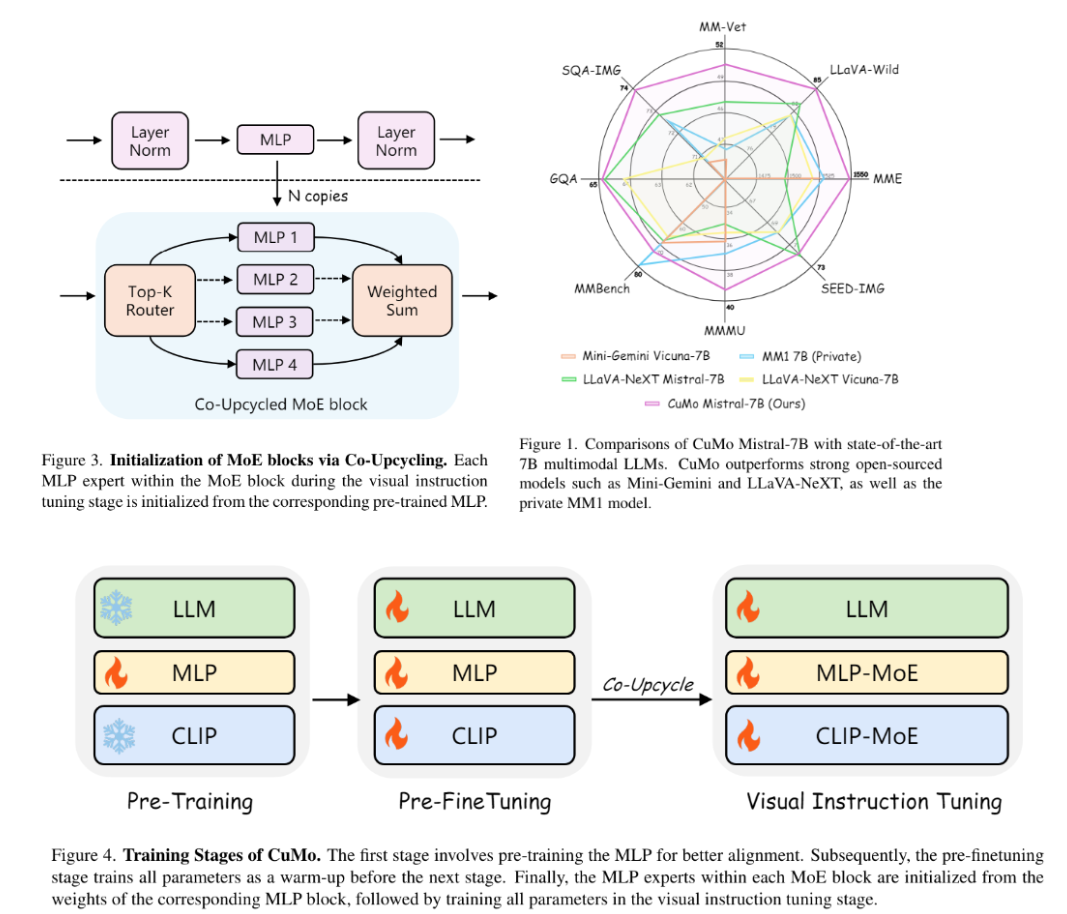
The key innovation is the concept of co-upcycling (Figure 3). Instead of training the sparse MoE modules from scratch, they are initialized from a pre-trained dense model before being fine-tuned. Co-upcycling provides a better initial point for the experts to specialize during training.
For training, CuMo employs a thoughtful three-stage training process:
1) Pre-train just the vision-language connector on image-text data like LLaVA to align the modalities.
2) Pre-finetune all model parameters jointly on caption data from ALLaVA to warm up the full system.
3) Finally, fine-tune with visual instruction data from datasets like VQAv2, GQA, and LLaVA-Wild, introducing the co-upcycled sparse MoE blocks along with auxiliary losses to balance the expert load and stabilize training. This comprehensive approach, integrating MoE sparsity into multimodal models through co-upcycling and careful training, allows CuMo to scale up efficiently compared to simply increasing model size.
The researchers evaluated CuMo models on a range of visual question-answering benchmarks like VQAv2 and GQA, as well as multimodal reasoning challenges such as MMMU and MathVista. Their models, as shown in Figure 1, trained solely on publicly available datasets, outperformed other state-of-the-art approaches within the same model size categories across the board. Even compact 7B parameter CuMo models matched or exceeded the performance of much larger 13B alternatives on many challenging tasks.
These impressive results highlight the potential of sparse MoE architectures combined with co-upcycling to develop more capable yet efficient multimodal AI assistants. As the researchers have open-sourced their work, CuMo could pave the way for a new generation of AI systems that can seamlessly understand and reason about text, images, and beyond.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
