In artificial intelligence, the surge in large language model (LLM) development has significantly transformed how machines understand and generate text, mimicking human conversation with remarkable accuracy. These models have become integral to various applications, including but not limited to content creation, automated customer support, and language translation. However, deploying these models in practical scenarios is hindered by their colossal size, often comprising billions of parameters, making their finetuning for specific tasks computationally expensive and technically challenging.
A novel approach has been developed that seeks to refine the finetuning process of LLMs without the need for extensive computational resources. Traditional methods involve updating a substantial portion of the model’s parameters, which demands significant memory and processing power. In contrast, the latest methodologies focus on adjusting only a small subset of parameters, thereby reducing the computational load. This technique, known as parameter-efficient finetuning (PEFT), has paved the way for more practical applications of LLMs by making the finetuning process faster and more accessible.
Carnegie Mellon University and Stanford University researchers have introduced a groundbreaking system named FlexLLM. This system is engineered to streamline the simultaneous handling of LLM inference and PEFT tasks on shared computational resources. FlexLLM leverages the inherent complementary nature of these tasks to optimize resource utilization, showcasing a significant leap in efficiency compared to traditional methods that treat these tasks separately.
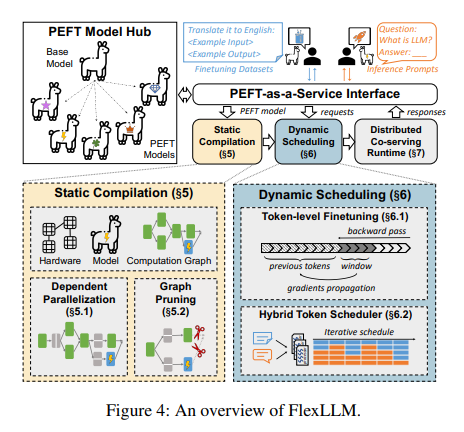
FlexLLM’s architecture is underpinned by two core innovations: a token-level finetuning mechanism and a suite of memory optimization strategies. The token-level approach breaks down the finetuning computation into smaller, manageable units, allowing for parallel processing of multiple tasks. This granularity reduces the overall memory footprint required for finetuning and accelerates the adaptation of LLMs to new tasks without compromising performance. Memory optimization further enhances this efficiency by implementing techniques such as graph pruning and dependent parallelization, which minimize the memory overhead associated with maintaining model states during the finetuning process.
As demonstrated in preliminary evaluations, FlexLLM’s performance marks a significant advancement in the field. FlexLLM maintained more than 80% of its peak finetuning throughput in scenarios characterized by heavy inference workloads, a feat that existing systems fail to achieve. This efficiency translates into improved GPU utilization for inference and finetuning tasks, showcasing FlexLLM’s capability to navigate the challenges posed by the resource-intensive nature of LLMs.

FlexLLM not only represents a technical breakthrough in optimizing LLM deployment but also promises to broaden the accessibility and applicability of these models across various domains. By significantly lowering the barriers to fine-tuning LLMs, this system opens up new avenues for innovation and research, enabling more entities to leverage the power of advanced natural language processing technologies.
In conclusion, the development of FlexLLM addresses a critical bottleneck in the deployment of LLMs by offering a more resource-efficient framework for their finetuning and inference tasks. This system enhances computational efficiency and lays the groundwork for the future expansion of LLM applications, making the most of artificial intelligence’s potential to mimic and understand human language.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
