Video generation technology stands out as a burgeoning field. This technology can potentially revolutionize various industries, including entertainment, advertising, and education, by offering new ways to create and manipulate video content. AI video generation leverages deep learning models to produce realistic videos, simulating natural movements and expressions, enabling content creators to bring their visions to life with unprecedented ease and flexibility.
One significant challenge in AI video generation is achieving high-quality outputs while managing computational costs and resource requirements. Traditional methods often require substantial computational power and can be costly, limiting accessibility for researchers and content creators. The complexity of video content, with its dynamic elements and temporal dimensions, poses unique challenges that necessitate innovative solutions to efficiently process and generate high-fidelity video sequences.
Current advancements in AI video generation technology have led to the development of models capable of producing high-quality videos for applications in movies, animation, games, and advertising. However, these models typically demand extensive computational resources and expertise to train and deploy, making them less accessible to a broader audience. There’s a growing need for more efficient and cost-effective solutions to democratize access to advanced video generation tools.
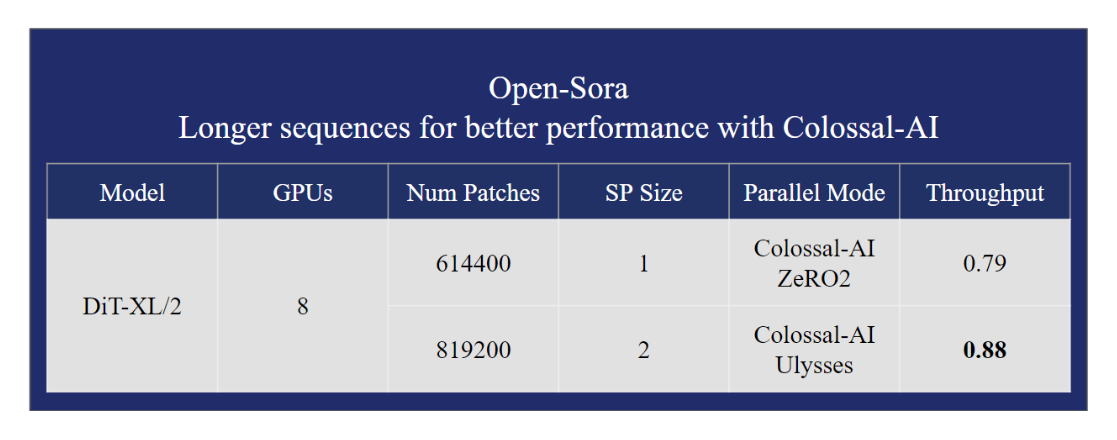
The research introduced by the Colossal-AI team with the development of Open-Sora, a replication architecture solution for the Sora model, marks a significant advancement in the field. This solution mirrors the capabilities of the Sora model in video generation and brings forth a remarkable reduction in training costs by 46%. Additionally, it extends the length of the model training input sequence to 819K patches, pushing the boundaries of what’s possible in AI-driven video generation.
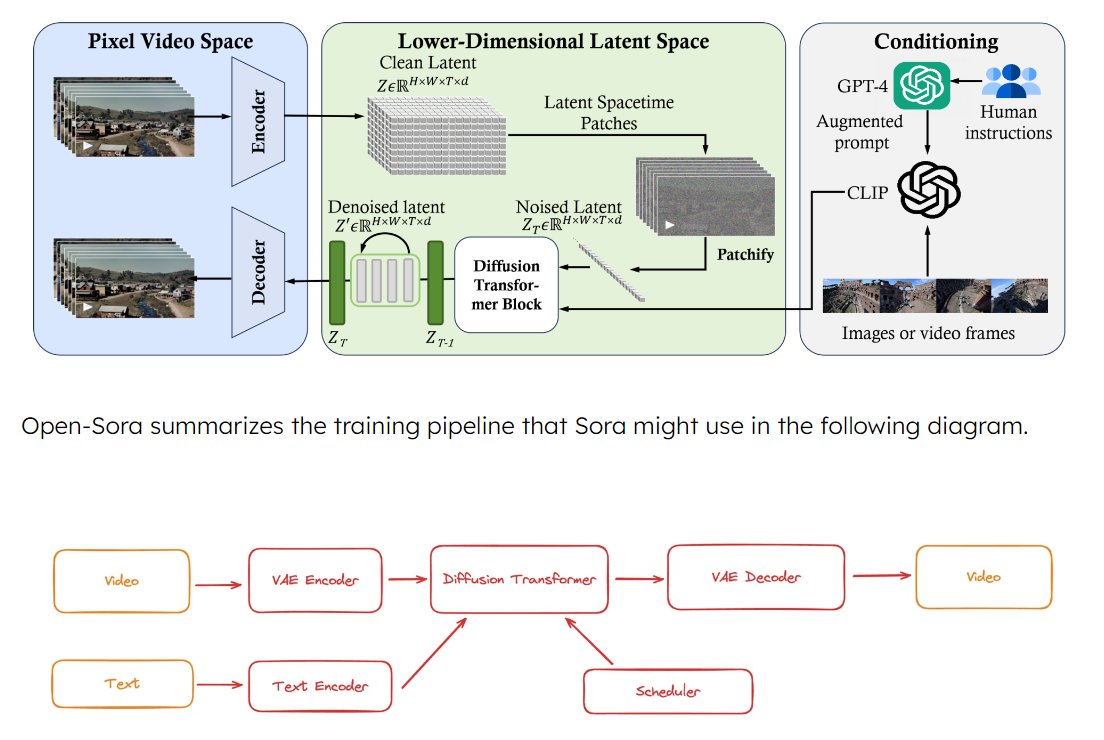
Open-Sora’s methodology revolves around a comprehensive training pipeline incorporating video compression, denoising, and decoding stages to process and generate video content efficiently. Using a video compression network, the model compresses videos into sequences of spatial-temporal patches in latent space, then refined through a Diffusion Transformer for denoising, followed by decoding to produce the final video output. This innovative approach allows for handling various sizes and complexities of videos with improved efficiency and reduced computational demands.
The performance of Open-Sora is noteworthy, showcasing over a 40% improvement in efficiency and cost reduction compared to baseline solutions. Furthermore, it enables the training of longer sequences, up to 819K+ patches, while maintaining or even enhancing training speeds. This performance leap demonstrates the solution’s capability to address the challenges of computational cost and resource efficiency in AI video generation. It also reassures the audience about its practicality and value, making high-quality video production more accessible to a wider range of users.
In conclusion, Open-Sora represents a pivotal development in the field of AI video generation, offering a cost-effective and efficient solution that broadens the horizons for content creators. By addressing key challenges such as computational cost and the complexity of processing dynamic video content, this research paves the way for the next generation of video generation technologies. The efforts of the open-source community and other stakeholders in further developing and optimizing Open-Sora promise to advance AI’s role in creative industries and beyond and make the audience feel included.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
