A major challenge in the field of natural language processing (NLP) is addressing the limitations of decoder-only Transformers. These models, which form the backbone of large language models (LLMs), suffer from significant issues such as representational collapse and over-squashing. Representational collapse occurs when different input sequences produce nearly identical representations, while over-squashing leads to a loss of sensitivity to specific tokens due to the unidirectional flow of information. These challenges severely hinder the ability of LLMs to perform essential tasks like counting or copying sequences accurately, which are fundamental for various computational and reasoning tasks in AI applications.
Current methods to tackle these challenges involve increasing model complexity and enhancing training datasets. Techniques such as using higher precision floating-point formats and incorporating more sophisticated positional encodings have been explored. However, these methods are computationally expensive and often impractical for real-time applications. Existing approaches also include the use of auxiliary tools to assist models in performing specific tasks. Despite these efforts, fundamental issues like representational collapse and over-squashing persist due to the inherent limitations of the decoder-only Transformer architecture and the low-precision floating-point formats commonly used.
Researchers from Google DeepMind and the University of Oxford propose a theoretical signal propagation analysis to investigate how information is processed within decoder-only Transformers. They focus on the representation of the last token in the final layer, which is crucial for next-token prediction. The proposed approach identifies and formalizes the phenomena of representational collapse and over-squashing. Representational collapse is shown to occur when distinct input sequences yield nearly identical representations due to low-precision floating-point computations. Over-squashing is analyzed by examining how information from earlier tokens is disproportionately squashed, leading to reduced model sensitivity. This approach is significant as it provides a new theoretical framework to understand these limitations and offers simple yet effective solutions to mitigate them.
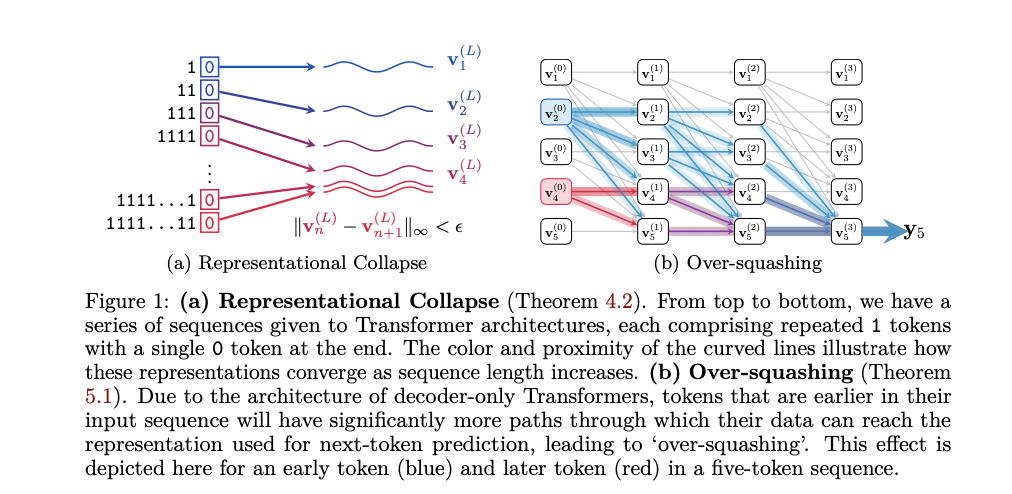
The proposed method involves a detailed theoretical analysis supported by empirical evidence. The researchers use mathematical proofs and experimental data to demonstrate representational collapse and over-squashing. They employ contemporary LLMs to validate their findings and illustrate how low floating-point precision exacerbates these issues. The analysis includes examining attention weights, layer normalization effects, and positional encoding decay. The researchers also discuss practical implications, such as the impact of quantization and tokenization on model performance, and propose adding additional tokens to long sequences as a practical solution to prevent representational collapse.
The results demonstrate that decoder-only Transformer models experience significant performance issues due to representational collapse and over-squashing, particularly in tasks requiring counting and copying sequences. Experiments conducted on contemporary large language models (LLMs) reveal a marked decline in accuracy as sequence length increases, with models struggling to differentiate between distinct sequences. The empirical evidence supports the theoretical analysis, showing that low-precision floating-point formats exacerbate these issues, leading to frequent errors in next-token prediction. Importantly, the proposed solutions, such as introducing additional tokens in sequences and adjusting floating-point precision, were empirically validated, leading to notable improvements in model performance and robustness in handling longer sequences. These findings highlight the critical need to address fundamental architectural limitations in LLMs to enhance their accuracy and reliability in practical applications.
In conclusion, the paper provides a thorough analysis of the limitations inherent in decoder-only Transformer models, specifically focusing on the issues of representational collapse and over-squashing. Through both theoretical exploration and empirical validation, the authors demonstrate how these phenomena impair the performance of large language models (LLMs) in essential tasks such as counting and copying sequences. The study identifies critical architectural flaws exacerbated by low-precision floating-point formats and proposes effective solutions to mitigate these problems, including the introduction of additional tokens and precision adjustments. These interventions significantly enhance model performance, making them more reliable and accurate for practical applications. The findings underscore the importance of addressing these fundamental issues to advance the capabilities of LLMs in natural language processing tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
