The surge in deploying Large Language Models (LLMs) such as GPT-3, OPT, and BLOOM across various digital interfaces, including chatbots and text summarization tools, has brought the critical need for optimizing their serving infrastructure to the forefront. LLMs are notorious for their huge sizes and the substantial computational resources they necessitate, presenting a trio of formidable challenges in their serving: efficiently utilizing hardware accelerators, managing the memory footprint, and ensuring minimal downtime during failures.
Researchers from MSR Project Fiddle Intern, ETH Zurich, Carnegie Mellon University, and Microsoft Research have meticulously developed a novel DéjàVu system to navigate these obstacles elegantly. At the heart of DéjàVu lies a versatile Key-Value (KV) cache streaming library, dubbed DéjàVuLib, which is ingeniously designed to streamline the serving process of LLMs. This system is groundbreaking for its approach to handling the bimodal latency inherent in prompt processing and token generation, a disparity that previously led to significant GPU underutilization.
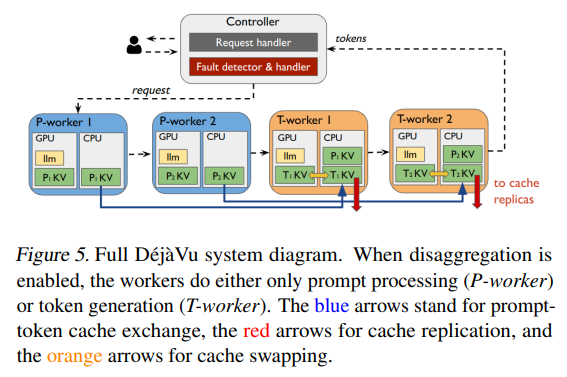
DéjàVu introduces a paradigm shift through prompt-token disaggregation, allocating distinct computational resources for each phase. This separation is tactically implemented to match the disparate memory and compute requirements of prompt processing and token generation. By aligning computational tasks with the most suitable hardware, DéjàVu ensures that GPUs are kept active, efficiently bridging the gap between the computationally intense prompt processing and the relatively uniform token generation phase.
A pivotal component of DéjàVu’s strategy is micro-batch swapping, an innovative technique designed to maximize GPU memory efficiency. This process involves dynamically swapping microbatches between GPU and CPU memory, thus allowing for larger batch sizes without the need for proportional increases in GPU memory. This not only enhances throughput but also allows for the serving of larger models under fixed hardware constraints, a significant leap forward in LLM serving technology.
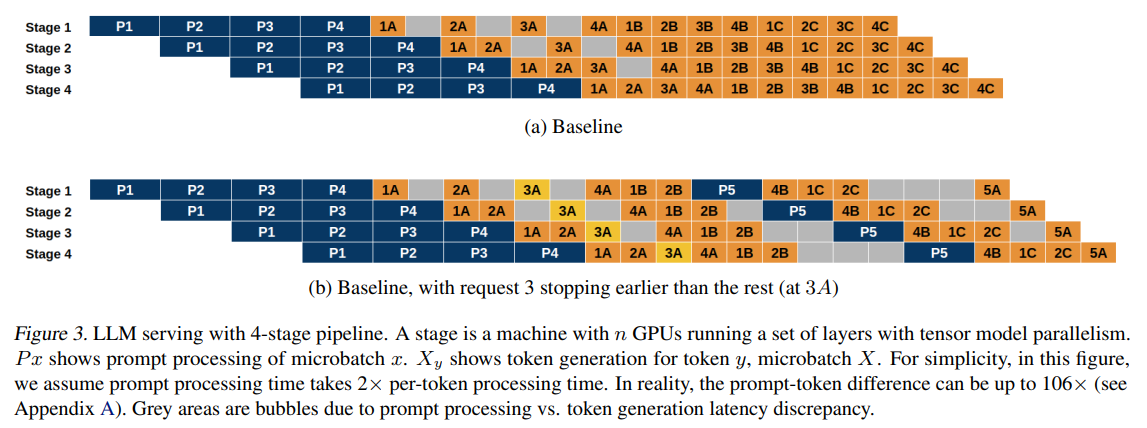
DéjàVu sets a new standard in system resilience through its state replication feature, which is designed to fortify the serving process against interruptions. By replicating the KV cache state across different memory stores, DéjàVu ensures that in the event of a failure, the system can quickly resume operations from the last known good state, minimizing the impact on overall serving performance. This approach dramatically reduces the redundancy and latency typically associated with recovery processes in traditional LLM serving systems.
The efficacy of DéjàVu demonstrated an ability to improve throughput by up to twice that of existing systems, a testament to its innovative methodologies. Such improvements are not just numerical triumphs but represent tangible enhancements in the user experience by reducing wait times and improving the trust in services powered by LLMs.
In crafting DéjàVu, researchers have addressed the existing inefficiencies in LLM serving and laid a blueprint for future innovations in this space. The system’s modular architecture, embodied by DéjàVuLib, ensures that it can be adapted and extended to meet the evolving demands of LLM applications. This adaptability, combined with the tangible improvements in efficiency and reliability, marks a significant milestone in realizing the potential of LLMs in everyday applications.
In conclusion, the research can be summarized in the following points:
- DéjàVu revolutionizes LLM serving with a focus on efficiency and fault tolerance, significantly outperforming current systems.
- The separation of prompt processing and token generation, coupled with micro-batch swapping, optimizes GPU utilization and memory management.
- State replication ensures robustness against failures, allowing for rapid recovery and minimal service interruption.
- Demonstrated throughput improvements of up to 2x highlight DéjàVu’s potential to enhance user experiences across LLM-powered services.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
