Data-Free Knowledge Distillation (DFKD) methods transfer knowledge from teacher to student models without real data, using synthetic data generation. Non-adversarial approaches employ heuristics to create data resembling the original, while adversarial methods utilize adversarial learning to explore distribution spaces. One-Shot Federated Learning (FL) addresses communication and security challenges in standard FL setups, enabling collaborative model training with a single communication round. However, traditional one-shot FL methods face limitations, including the need for public datasets and a focus on model-homogeneous settings.
Existing approaches like DENSE attempt to address data heterogeneity using DFKD but struggle with limited knowledge extraction due to single-generator server setups. Previous methods, including DENSE and FedFTG, restricted training space coverage and knowledge transfer effectiveness. These limitations highlight the need for innovative solutions to enhance model training in federated settings, particularly in handling model heterogeneity and improving synthetic data generation quality. The development of more comprehensive approaches, such as the DFDG method, aims to address these challenges and advance the field of federated learning.
A team of researchers from china introduced DFDG, a novel one-shot Federated Learning method addressing challenges in existing approaches. Current techniques often rely on public datasets and single generators, limiting training space coverage and hindering global model robustness. DFDG employs dual generators trained adversarially to expand training space exploration, focusing on fidelity, transferability, and diversity. It introduces a cross-divergence loss to minimize generator output overlap. The method aims to overcome limitations in data privacy, communication costs, and model performance in heterogeneous client data scenarios. Extensive experiments on image classification datasets demonstrate DFDG’s superior performance compared to state-of-the-art baselines, validating its effectiveness in enhancing global model training in federated settings.
The DFDG method employs dual generators trained adversarially to enhance one-shot Federated Learning. This approach explores a broader training space by minimizing output overlap between generators. The generators are evaluated on fidelity, transferability, and diversity, ensuring effective representation of local data distributions. A cross-divergence loss function is introduced to reduce generator output overlap, maximizing training space coverage. The methodology focuses on generating synthetic data that mimics local datasets without direct access, addressing privacy concerns, and improving global model performance in heterogeneous client scenarios.
Experiments are conducted on various image classification datasets, comparing DFDG against state-of-the-art baselines like FedAvg, FedFTG, and DENSE. The setup simulates a centralized network with ten clients, using a Dirichlet process to model data heterogeneity and exponentially distributed resource budgets to reflect model heterogeneity. Performance is primarily evaluated using global test accuracy (G.acc), with experiments repeated over three seeds for reliability. This comprehensive experimental design validates DFDG’s effectiveness in enhancing one-shot Federated Learning across diverse scenarios and data distributions.
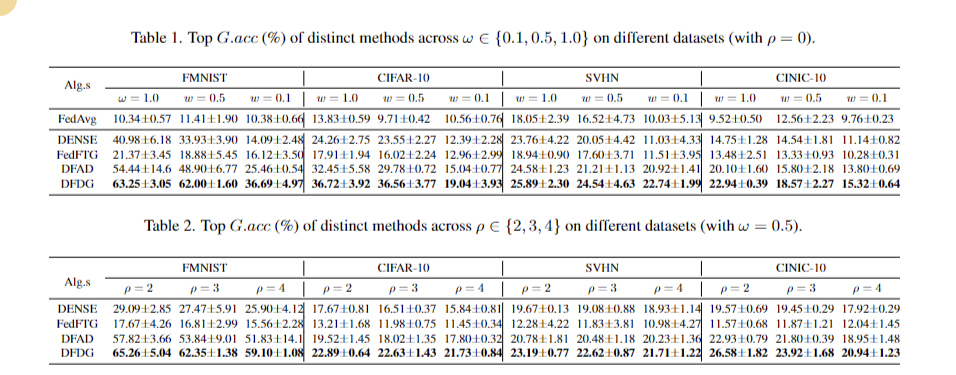
The experimental results demonstrate DFDG’s superior performance in one-shot federated learning across various scenarios of data and model heterogeneity. With data heterogeneity concentration parameter ω varying among {0.1, 0.5, 1.0} and model heterogeneity parameters σ = 2 and ρ among {2, 3, 4}, DFDG consistently outperformed baselines. It achieved accuracy improvements over DFAD of 7.74% for FMNIST, 3.97% for CIFAR-10, 2.01% for SVHN, and 2.59% for CINIC-10. DFDG’s effectiveness was further validated in challenging tasks like CIFAR-100, Tiny-ImageNet, and FOOD101 with varying client numbers N. Using global test accuracy (G.acc) as the primary metric, experiments repeated over three seeds affirm DFDG’s capability to enhance one-shot federated learning performance in heterogeneous environments.
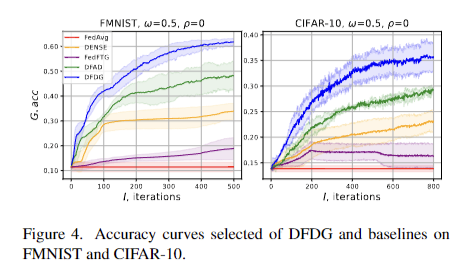
In conclusion, DFDG introduces a novel data-free one-shot federated learning method utilizing dual generators to explore a broader training space for local models. The method operates in an adversarial framework with dual-generator training and dual-model distillation stages. It emphasizes generator fidelity, transferability, and diversity, introducing a cross-divergence loss to minimize generator output overlap. The dual-model distillation phase uses synthetic data from trained generators to update the global model. Extensive experiments across various image classification tasks demonstrate DFDG’s superiority over state-of-the-art baselines, confirming significant accuracy gains. DFDG effectively addresses data privacy and communication challenges while enhancing model performance through innovative generator training and distillation techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI
