Reinforcement learning (RL) is predicated on agents learning to make decisions by interacting with an environment. RL has achieved remarkable feats in various applications, including games, robotics, and autonomous systems. The goal is to develop algorithms that enable agents to perform tasks efficiently by maximizing cumulative rewards through trial-and-error interactions. By continuously adapting to new data, these algorithms help improve performance over time, making RL a vital component in developing intelligent systems.
A significant challenge in RL is sample inefficiency, where agents require extensive interactions with the environment to learn effective policies. This limitation hinders the practical application of RL in real-world scenarios, especially in environments where obtaining samples is costly or time-consuming. Addressing this problem is crucial for deploying RL in practical applications, such as autonomous driving and robotic automation, where real-world testing can be expensive and time-consuming.
Existing research includes world models like SimPLe and Dreamer, which train RL agents in simulated environments. SimPLe applies world models to Atari, focusing on sample efficiency, while Dreamer introduces learning from latent space. DreamerV2 and DreamerV3 further improve this with discrete latents and fixed hyperparameters. Other models like TWM and STORM adapt Dreamer’s architecture using transformers. IRIS uses a discrete autoencoder and autoregressive transformer to model environment dynamics over time.
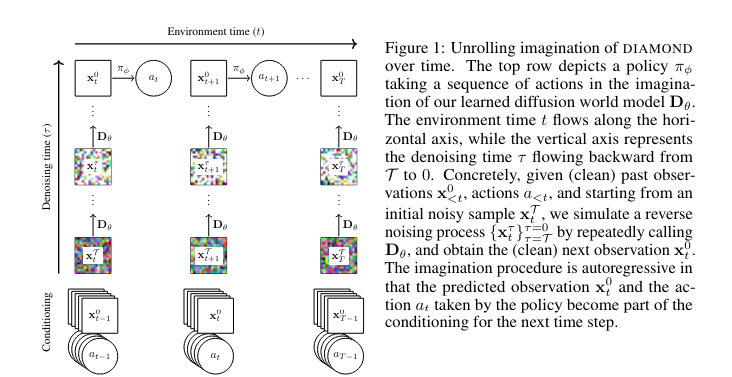
Researchers from the University of Geneva, the University of Edinburgh, and Microsoft Research have introduced DIAMOND (DIffusion As a Model Of eNvironment Dreams), a novel RL agent trained using a diffusion-based world model. DIAMOND leverages the strengths of diffusion models, which are prominent in high-resolution image generation. By integrating these models into world modeling, DIAMOND aims to preserve visual details often lost in traditional methods, thereby improving the fidelity of simulated environments and the overall training process.
DIAMOND’s methodology involves training the agent in a diffusion-based world model, where the environment’s visual details are preserved more effectively compared to traditional discrete latent variable models. The diffusion process reverses a noising procedure, creating detailed and accurate environment simulations that aid the agent’s training and performance. This approach requires careful design choices to ensure the diffusion model remains stable over long time horizons and maintains computational efficiency. The research team implemented several key design choices, including enhanced visual representation techniques and adaptive noise schedules, to optimize the diffusion process for world modeling.
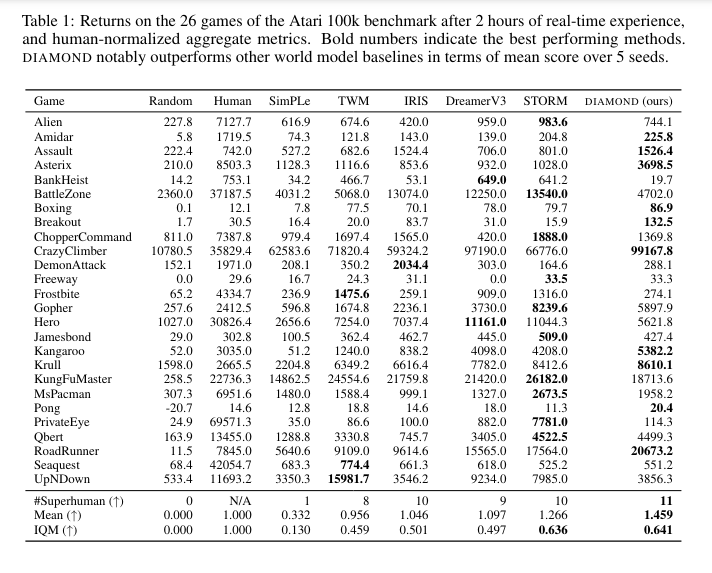
The performance of DIAMOND is evaluated on the Atari 100k benchmark, where it achieves a mean human-normalized score of 1.46, setting a new benchmark for agents trained entirely within a world model. The benchmark involves 26 games, each testing different aspects of the agent’s capabilities. DIAMOND’s performance significantly surpasses other world model-based agents. For example, it achieves scores of 4031.2 on Breakout and 12250 on UpNDown, highlighting its superior ability to learn and adapt in complex environments. This improved performance is attributed to the enhanced visual detail and stability the diffusion model provides, leading to better decision-making and learning efficiency. The researchers demonstrated that DIAMOND not only performs well in scores but also shows consistency in its decision-making process across different games.
In conclusion, DIAMOND represents a significant advancement in RL by addressing the challenge of sample inefficiency through improved world modeling. The researchers’ diffusion model approach enhances visual detail and stability, leading to superior performance in training RL agents. This innovative method has the potential to revolutionize how RL agents are trained, making them more efficient and capable of operating in complex, real-world environments. Integrating diffusion models into world modeling marks a step forward in developing more robust and effective RL systems, paving the way for broader applications and improved AI performance.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
