Sampling from complex, high-dimensional target distributions, such as the Boltzmann distribution, is crucial in many scientific fields. For instance, predicting molecular configurations depends on this type of sampling. Combinatorial Optimization (CO) can be seen as a distribution learning problem where the samples correspond to solutions of CO problems, but it is challenging to achieve unbiased samples. Areas like CO or lattice models in physics involve discrete target distributions, which can be approximated using products of categorical distributions. Although product distributions are computationally efficient, they lack expressivity because they cannot capture statistical interdependencies.
This paper discusses several existing methods. First, the approach includes Variational Autoencoders, which are latent variable models. Here, samples are generated by first drawing latent variables from a prior distribution, which are then processed by a neural network-based stochastic decoder. Next, the approach covers Diffusion Models, another type of latent variable model, which is usually trained using samples from a data distribution. Neural optimization is another technique that uses neural networks to find the best solution to a given objective, which is another approach that uses neural networks. Moreover, two more methods are Approximate Likelihood Models in Neural Probabilistic Optimization and Neural Combinatorial Optimization.
Researchers from Johannes Kepler University, Austria, ELLIS Unit Linz, and NXAI GmbH have introduced Diffusion for Unsupervised Combinatorial Optimization (DiffUCO), a method that allows for the application of latent variable models like diffusion models in the problem of data-free approximation of discrete distributions. It uses an upper bound on the reverse Kullback-Leibler divergence as a loss function, and its performance improves as the number of diffusion steps used during training increases. Moreover, the solution quality during the inference can be improved by applying more diffusion steps.
DiffUCO addresses challenges in CO and obtains state-of-the-art performance across various benchmarks. Researchers also introduced a method called Conditional Expectation (CE) which is a more efficient version of a commonly used sampling technique. By combining this method with the diffusion model, high-quality solutions to CO problems can be generated efficiently. This framework produces a highly efficient and general way of using latent variable models like diffusion models for approximating data-free discrete distributions. Due to the discrete nature of UCO, two discrete noise distributions applied are Categorical Noise Distribution and Annealed Noise Distribution.
In the experiment, researchers focused on many sets including Maximum Independent Set(MIS) and Minimum Dominating Set (MDS). In MIS, the proposed model was tested on RB-small and RB-large. The CE and CE-ST variants of DiffUCO obtained the best results on RB-large and slightly outperformed LTFT on RB-small. In MDS, the goal was to find the set with the lowest number of vertices in a graph so that each node has at least one neighbor within the set. The model was tested on BA-small and BA-large datasets, where DiffUCO and its variants outperform all other methods on both datasets.
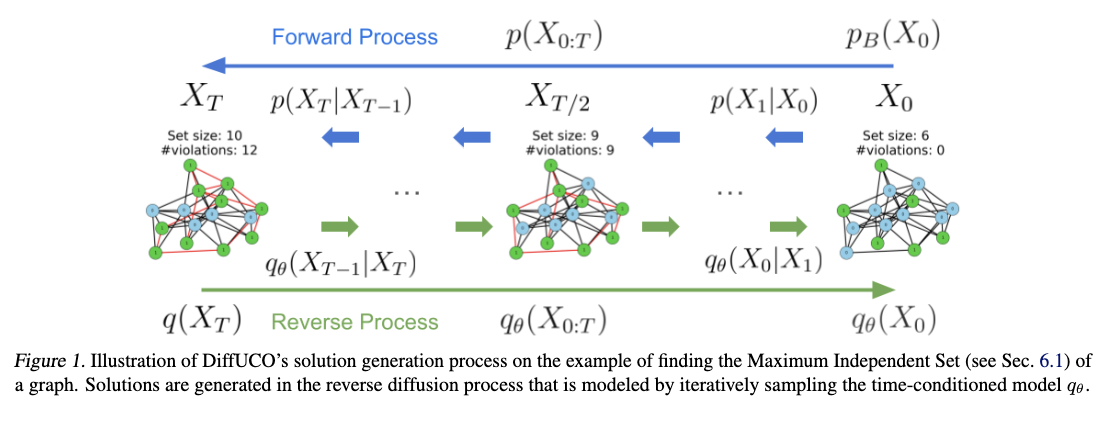
In conclusion, researchers proposed Diffusion for Unsupervised Combinatorial Optimization (DiffUCO). This method enables the use of latent variable models, such as diffusion models, for approximating data-free discrete distributions. DiffUCO outperforms recently presented methods on a wide range of benchmarks, and its solution quality improves when variational annealing and additional diffusion steps during inference are applied. However, the model is memory- and time-expensive when trained on large datasets with high connectivity. Future work should focus on improving these factors to make the model more efficient.
Check out the Paper and Code. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
