The relentless advancement in natural language processing (NLP) has ushered in an era of large language models (LLMs) capable of performing various complex tasks with unprecedented accuracy. These models, however, come at the cost of extensive computational and memory requirements, limiting their deployment in resource-constrained environments. A promising solution to mitigate these limitations lies in model quantization, which aims to reduce the model’s size and computational demands without significantly affecting its performance.
Quantization, while not a novel concept, has faced its share of challenges, particularly when applied to LLMs. Traditional methods often rely on a subset of training data for calibration, leading to potential overfitting and a loss in the model’s ability to generalize to new, unseen tasks. This is where the Tencent research team’s development of EasyQuant introduces a groundbreaking approach. By pioneering a data-free and training-free quantization algorithm specifically tailored for LLMs, EasyQuant aims to reduce the quantization error while maintaining significantly and, in some cases, enhancing the model’s performance.
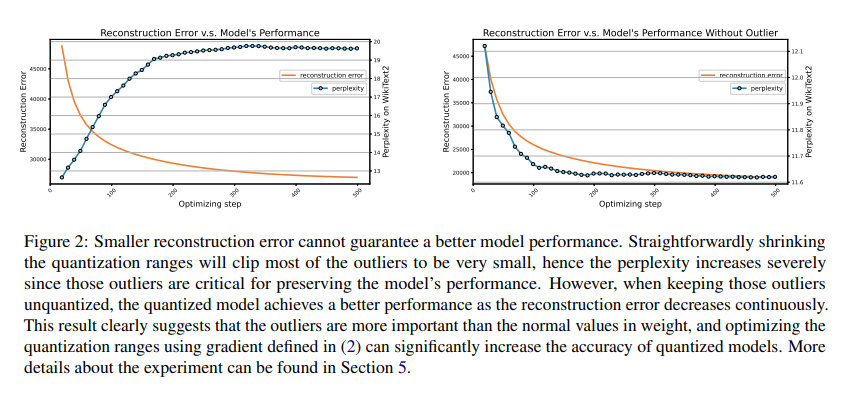
The core insight behind EasyQuant lies in its innovative handling of two critical aspects that significantly impact the quantization process: the presence of outliers in the weight distribution and the optimization of quantization ranges. Traditional quantization methods often overlook these aspects, leading to increased errors and reduced model performance. EasyQuant, however, identifies and preserves the outliers, those weight values that deviate significantly from the norm, while optimizing the quantization range for the remaining weights. This method minimizes the quantization error and ensures that the performance of the quantized model closely matches that of the original, non-quantized version.
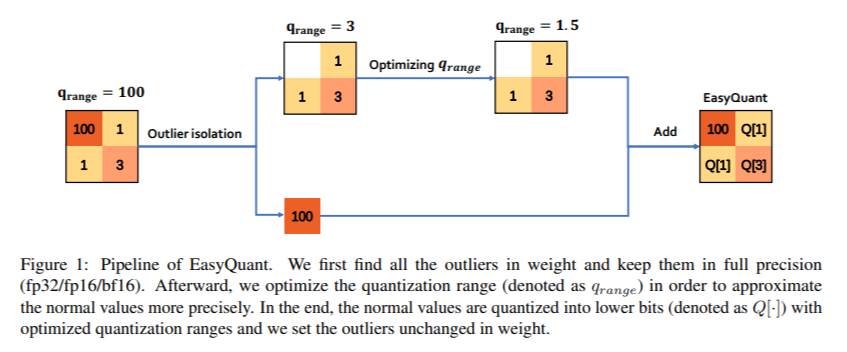
One of EasyQuant’s most compelling advantages is its exceptional operational efficiency. Unlike data-dependent methods that require hours to calibrate and adjust the quantized model using a subset of training data, EasyQuant operates in a data-free manner, significantly reducing the time required for quantization. The researchers demonstrated that LLMs with over 100 billion parameters could be quantized in just a few minutes, a remarkable achievement that underscores the method’s potential to revolutionize the deployment of LLMs across applications and devices.
Through a series of experiments, the Tencent team showcased that EasyQuant not only preserves but, in some cases, improves the LLMs’ efficiency across various benchmarks. This achievement is particularly notable given that EasyQuant operates without training data, thus eliminating the risk of overfitting and ensuring the model’s ability to generalize across different tasks.
In summary, EasyQuant represents a significant leap forward in the quantization of large language models, characterized by:
- A data-free and training-free quantization process that maintains or enhances model performance.
- The innovative handling of weight outliers and optimization of quantization ranges to minimize quantization error.
- Operational efficiency that allows for rapid quantization of even the largest LLMs.
- The ability to generalize across tasks without the risk of overfitting associated with data-dependent methods.
This innovative approach paves the way for more efficient deployment of LLMs in resource-constrained environments. It opens new avenues for their application, making the benefits of advanced natural language processing technologies more accessible to a broader audience.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
