Developing large language models (LLMs) in artificial intelligence, such as OpenAI’s GPT series, marks a transformative era, bringing profound impacts across various sectors. These sophisticated models have become cornerstones for generating contextually rich and coherent text outputs, facilitating applications from automated content creation to nuanced customer service interactions. However, when integrated with external tools, their capabilities extend beyond text generation.
Despite the exciting prospects, integrating LLMs with external tools reveals a pivotal challenge: the precision with which these models utilize tools still needs to be improved. This gap is significant; for LLMs to truly extend their utility and application, they must access various tools and employ them with high accuracy. Current statistics, including those from groundbreaking models like GPT-4, show a tool usage correctness rate that falls short of the mark, emphasizing the necessity for enhanced methodologies in tool-augmented LLM applications.
Studies have previously concentrated on expanding the toolset available to LLMs and simplifying the integration of new tools. But they scarcely scratch the surface of the underlying issue: the accuracy of tool utilization. This aspect is crucial; as LLMs venture into executing tasks with tangible impacts, the stakes of accurate tool usage escalate, especially in scenarios where incorrect actions could lead to adverse outcomes. The quest for a solution brings us to an innovative approach inspired by nature’s learning mechanisms.
Researchers from Ohio State University and Microsoft Semantic Machines have introduced Simulated Trial and Error (STE), a method inspired by the cognitive learning processes observed in humans and other intelligent organisms. This pioneering approach seeks to refine LLMs’ mastery over tools through a process reminiscent of human learning, combining the elements of imagination, trial and error, and memory. LLMs can use tools iteratively, learning from each interaction’s feedback to hone their approach and significantly improve accuracy. This method embodies a shift from a static understanding of tool operation towards a dynamic, interactive learning model that mirrors biological processes.
At the center of STE lies a dual-memory system consisting of short-term and long-term components designed to enhance the exploration capabilities of LLMs. The short-term memory focuses on the immediate past, allowing LLMs to learn from recent trials and refine their tool usage strategies accordingly. In contrast, the long-term memory component builds a reservoir of past experiences, guiding LLMs in their long-term learning trajectory and enabling them to draw upon knowledge for future interactions. This sophisticated memory framework underpins the STE method, fostering LLMs’ more nuanced and effective tool usage.
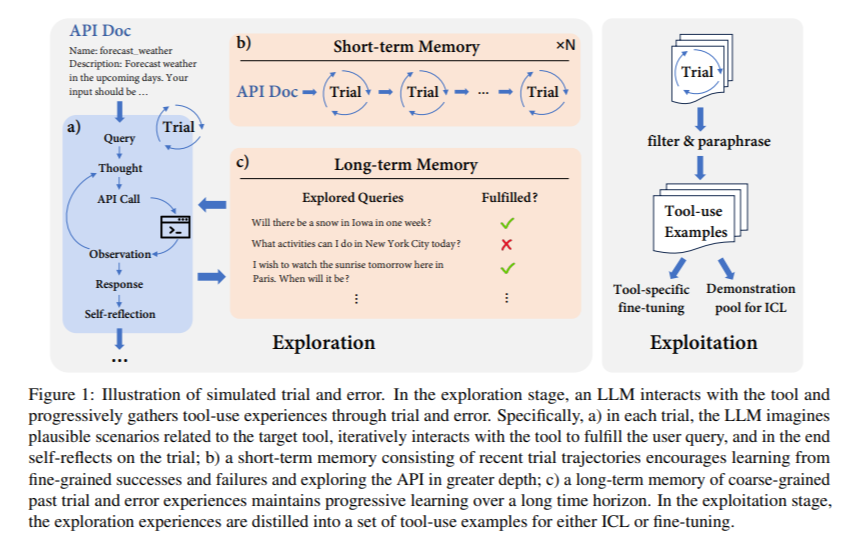
The efficacy of STE has been rigorously tested on the ToolBench platform, revealing remarkable improvements in tool usage accuracy among LLMs. Models augmented with STE surpassed traditional benchmarks, including GPT-4, but demonstrated superior performance across both in-context learning and fine-tuning scenarios. These findings underscore STE’s transformative potential in enhancing tool-augmented LLMs’ operational efficiency, propelling them towards more reliable and effective tool usage in practical applications.

In conclusion, integrating LLMs with external tools, powered by the innovative STE method, heralds a new chapter in artificial intelligence. This approach not only rectifies the pressing issue of tool usage accuracy but also paves the way for broader and more impactful applications of LLMs across diverse sectors. With its biologically inspired learning mechanisms, the STE method assists in the evolution of LLM.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
