Large language models (LLMs) have shown promise in powering autonomous agents that control computer interfaces to accomplish human tasks. However, without fine-tuning on human-collected task demonstrations, the performance of these agents remains relatively low. A key challenge lies in developing viable approaches to build real-world computer control agents that can effectively execute complex tasks across diverse applications and environments. The current methodologies, which rely on pre-trained LLMs without task-specific fine-tuning, have achieved only limited success, with reported task success rates ranging from 12% to 46% in recent studies.
Previous attempts to develop computer control agents have explored various approaches, including zero-shot and few-shot prompting of large language models, as well as fine-tuning techniques. Zero-shot prompting methods utilize pre-trained LLMs without any task-specific fine-tuning, while few-shot approaches provide a small number of examples to the LLM. Fine-tuning methods involve further training the LLM on task demonstrations, either end-to-end or for specific capabilities like identifying interactable UI elements. Notable examples include SeeAct, WebGPT, WebAgent, and Synapse. However, these existing methods have limitations in terms of performance, domain generalization, or the complexity of tasks they can handle effectively.
Google DeepMind and Google researchers present ANDROIDCONTROL, a large-scale dataset of 15,283 human demonstrations of tasks performed in Android apps. A key feature of ANDROIDCONTROL is that it provides both high-level and low-level human-generated instructions for every task, enabling the investigation of task complexity levels that models can handle while offering richer supervision during training. Also, it is the most diverse UI control dataset to date, comprising 15,283 unique tasks across 833 different Android apps. This diversity allows for the generation of multiple test splits to measure performance both in and out of the task domain covered by the training data. The proposed method involves utilizing ANDROIDCONTROL to quantify how fine-tuning scales when applied to low and high-level tasks, both in-domain and out-of-domain, and comparing fine-tuning approaches with various zero-shot and few-shot baselines.

The ANDROIDCONTROL dataset was collected over a year through crowdsourcing. Crowdworkers were provided with generic feature descriptions for apps across 40 different categories and asked to instantiate these into specific tasks involving apps of their choice. This approach led to the collection of 15,283 task demonstrations spanning 833 Android apps, including popular apps as well as less popular or regional ones. For each task, annotators first provided a high-level natural language description. Then, they performed the task on a physical Android device, with their actions and associated screenshots captured. Importantly, annotators also provided low-level natural language descriptions of each action before executing it. The resulting dataset contains both high-level and low-level instructions for each task, enabling analysis of different task complexity levels. Careful dataset splits were created to measure in-domain and out-of-domain performance.
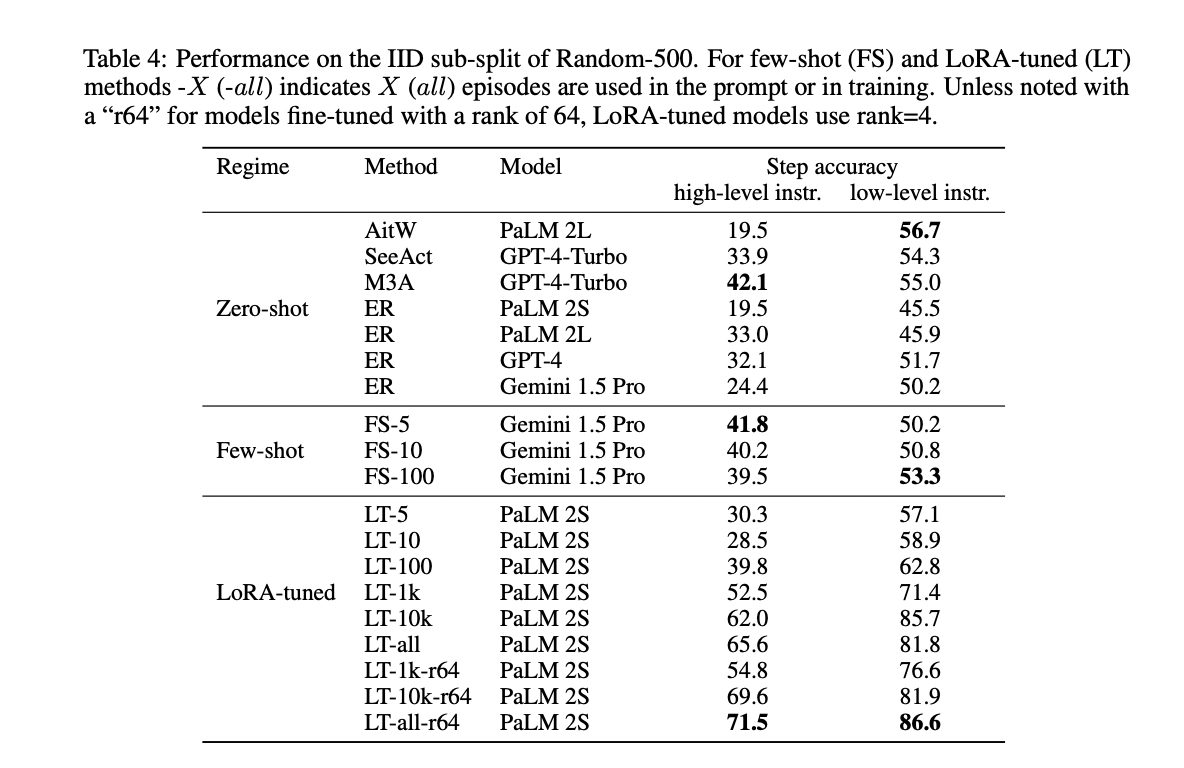
The results show that for in-domain evaluation on the IDD subset, LoRA-tuned models outperform zero-shot and few-shot methods when trained with sufficient data, despite using the smaller PaLM 2S model. Even with just 5 training episodes (LT-5), LoRA-tuning surpasses all non-finetuned models on low-level instructions. For high-level instructions, 1k episodes are required. The best LoRA-tuned model achieves 71.5% accuracy on high-level and 86.6% on low-level instructions. Among zero-shot methods, AitW with PaLM 2L performs best (56.7%) on low-level, while M3A with GPT-4 is highest (42.1%) on high-level instructions, likely benefiting from incorporating high-level reasoning. Surprisingly, few-shot performance is mostly inferior to zero-shot across the board. The results highlight the strong in-domain benefits of fine-tuning, especially for more data.
This work introduced ANDROIDCONTROL, a large and diverse dataset designed to study model performance on low and high-level tasks, both in-domain and out-of-domain, as training data is scaled. Through evaluation of LoRA fine-tuned models on this dataset, it is predicted that achieving 95% accuracy on in-domain low-level tasks would require around 1 million training episodes, while 95% episode completion rate on 5-step high-level in-domain tasks would require approximately 2 million episodes. These results suggest that while potentially expensive, fine-tuning may be a viable approach for obtaining high in-domain performance across task complexities. However, out-of-domain performance requires one to two orders of magnitude more data, indicating that fine-tuning alone may not scale well and additional approaches may be beneficial, especially for robust performance on out-of-domain high-level tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
