Fusion oncoproteins, formed by chromosomal translocations, are key drivers in many cancers, especially pediatric ones. These chimeric proteins are difficult to target with drugs due to their large, disordered structures and lack of distinct binding pockets. Traditional drug design methods, like small molecules, often fail because they need more specificity or bind crucial cellular proteins. Protein language models (pLMs) have emerged as a promising tool, offering detailed sequence-based insights into protein function. Despite success with various proteins, current plans still need to include training on fusion oncoproteins, limiting their application in designing therapeutics for these challenging targets.
Researchers at Duke University have developed FusOn-pLM, a new protein language model tailored for fusion oncoproteins. This model fine-tunes the advanced ESM-2 pLM, specifically on fusion oncoprotein sequences from large databases. They introduced an innovative masked language modeling approach focusing on key residues likely involved in protein interactions. This method improves the representation of fusion oncoproteins, outperforming the base ESM-2 model and other embeddings in various benchmarks. The enhanced embeddings are designed to aid in the therapeutic targeting these challenging proteins. FusOn-pLM is publicly accessible for further research and applications.
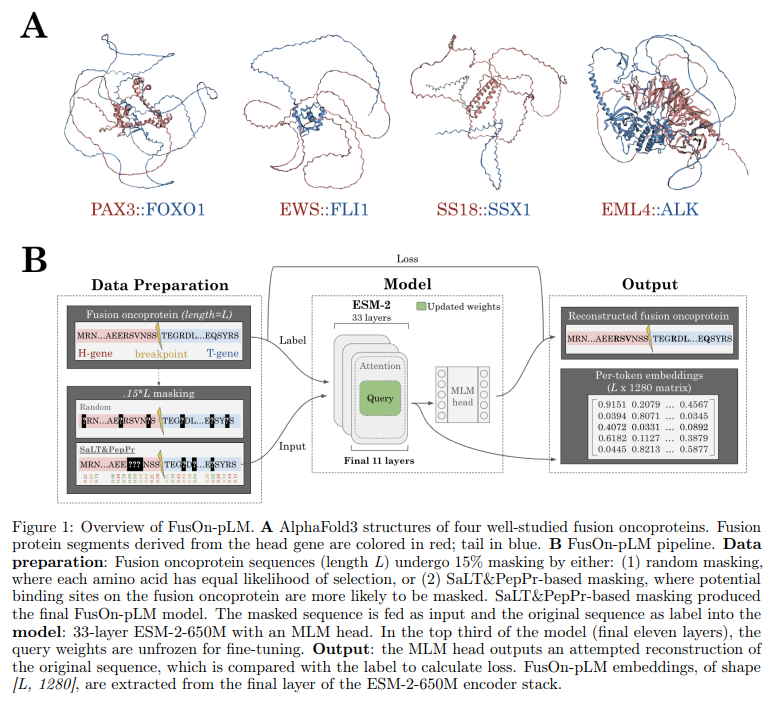
The training dataset for FusOn-pLM was meticulously curated from FusionPDB and FOdb databases, gathering 41,420 sequences from FusionPDB and 4,536 from FOdb. Only sequences containing the 20 natural amino acids and under 2000 amino acids in length were selected, ensuring they fit within GPU memory constraints. After removing duplicates from overlapping entries, 177 FOdb sequences were set aside for benchmarking. The remaining sequences underwent clustering using the MMSeqs2 tool, applying a minimum sequence identity threshold of 30% and an 80% coverage threshold. The clusters were divided into training, validation, and testing sets in an 80/10/10 ratio. For benchmarking, specific datasets from FOdb were curated for tasks like predicting the tendency of fusion oncoproteins to form condensates and their cellular localization. Additional datasets were used to predict cancer-related disease outcomes and analyze the properties of intrinsically disordered regions (IDRs).
FusOn-pLM’s effectiveness was evaluated using several benchmark tasks, including predicting phase separation of fusion oncoproteins, their localization in the cell, and their associations with specific cancers like breast invasive carcinoma and stomach adenocarcinoma. A targeted probabilistic masking strategy was employed to improve model comprehension, focusing on amino acids likely to participate in protein-protein interactions identified through SaLT&PepPr predictions. This masking strategy, applied to 15% of each sequence, enhances the model’s ability to recognize the interaction points within fusion oncoproteins. During training, the model fine-tuned the advanced ESM-2-650M model by unfreezing the weights and biases of its final layers. FusOn-pLM’s embeddings were benchmarked against other types, including those from ESM-2-650M, and manually curated FOdb embeddings, demonstrating superior performance in disorder prediction and capturing key physicochemical properties.
FusOn-pLM’s embeddings were enhanced using probabilistic masking, particularly the SaLT&PepPr-based approach, leading to optimal performance. The model was evaluated on various tasks, demonstrating superior performance in predicting the behavior and properties of fusion oncoproteins, such as their propensity to form puncta and their cellular localization. Additionally, FusOn-pLM excelled in identifying intrinsically disordered regions and their physicochemical properties, outperforming other embedding methods. Visualization techniques showed that FusOn-pLM embeddings distinctly separate fusion oncoproteins from their components, reflecting their unique characteristics and biological relevance.
In conclusion, FusOn-pLM, an ESM-2-based protein language model, is specifically tuned to capture the unique properties of fusion oncoproteins, which are typically disordered and contribute to cancer development. Unlike traditional models and embeddings like FOdb, FusOn-pLM excels in tasks related to fusion oncoproteins and effectively distinguishes these proteins from their components. Future work aims to utilize FusOn-pLM to design targeted protein degraders and integrate post-translational modifications for more precise therapeutic interventions. This model represents a significant advancement in biologics for treating fusion protein cancers.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
