Nowadays, many people read audiobooks instead of books or other media. Audiobooks not only let current readers enjoy information while on the road, but they may also help make content accessible to groups, including children, the visually impaired, and anyone learning a new language. Traditional audiobook production techniques take time and money and can result in varying recording quality, such as professional human narration or volunteer-driven initiatives like LibriVox. Due to these issues, keeping up with the rising number of published books takes time and effort.
However, automatic audiobook creation has historically suffered due to the robotic nature of text-to-speech systems and the difficulty in deciding what text should not be read aloud (such as tables of contents, page numbers, figures, and footnotes). They provide a method for overcoming the abovementioned difficulties by creating high-quality audiobooks from various online e-book collections. Their approach specifically incorporates recent developments in neural text-to-speech, expressive reading, scalable computation, and automated recognition of pertinent content to produce thousands of natural-sounding audiobooks.
They contribute over 5,000 audiobooks worth of speech, totaling over 35,000 hours, to the open source. They also provide demonstration software that enables conference participants to make their audiobooks by reading any book from the library aloud in their voices using only a brief sample of sound. This work introduces a scalable method for converting HTML-based e-books to excellent audiobooks. SynapseML, a scalable machine learning platform that enables distributed orchestration of the whole audiobook generation process, is the foundation for their pipeline. Their distribution chain starts with thousands of Project Gutenberg-provided free e-books. They deal mostly with the HTML format of these e-books since it lends itself to automated parsing, the best of all the available formats for these publications.
As a result, we could organize and visualize the complete collection of Project Gutenberg HTML pages and identify many sizable groups of similarly structured files. The major classes of e-books were transformed into a standard format that could be automatically processed using a rule-based HTML normalizer created using these collections of HTML files. Thanks to this approach, we developed a system that could swiftly and deterministically parse a huge number of books. Most significantly, it allowed us to focus on the files that would result in high-quality recordings when read.
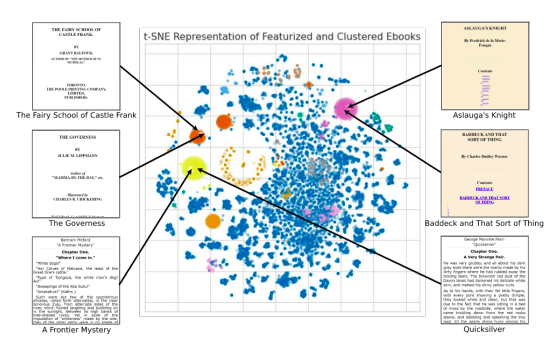
The results of this approach for clustering are shown in Figure 1, which illustrates how various groups of similarly organized electronic books spontaneously arise in the Project Gutenberg collection. After processing, a plain text stream may be extracted and fed into text-to-speech algorithms. There are many reading techniques required for various audiobooks. A clear, objective voice is best for nonfiction, whereas an expressive reading and a little “acting” are better for fiction with dialogue. However, in their live demonstration, they will provide customers the option to alter the text’s voice, pace, pitch, and intonation. For the bulk of the books, they utilize a clear and neutral neural text-to-speech voice.
They use zero-shot text-to-speech techniques to transfer the voice effectively features from a small number of enrolled recordings to duplicate a user’s voice. By doing this, a user may rapidly produce an audiobook in their voice, utilizing just a tiny bit of audio that has been captured. They employ an automated speaker and emotion inference system to dynamically alter the reading voice and tone based on context to produce an emotional text reading. This enhances the lifelikeness and interest of sequences with several people and dynamic interaction.
To do this, they first divide the text into narrative and conversation, designating a different speaker for each line of dialogue. Then, self-supervised, they predict each dialogue’s emotional tone. Finally, they use the multi-style and contextual-based neural text-to-speech model introduced to assign distinct voices and emotions to the narrator and the character conversations. They think this approach might significantly increase the availability and accessibility of audiobooks.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
