Deep reinforcement learning (DRL) faces a critical challenge due to the instability caused by “churn” during training. Churn refers to unpredictable changes in the output of neural networks for states that are not included in the training batch. This problem is particularly troublesome in reinforcement learning (RL) because of its inherently non-stationary nature, where policies and value functions continuously evolve as new data is introduced. Churn leads to significant instabilities in learning, causing erratic updates to both value estimates and policies, which can result in inefficient training, suboptimal performance, and even catastrophic failures. Addressing this challenge is essential for improving the reliability of DRL in complex environments, enabling the development of more robust AI systems in real-world applications like autonomous driving, robotics, and healthcare.
Current methods to mitigate instability in DRL, such as value-based algorithms (e.g., DoubleDQN) and policy-based methods (e.g., Proximal Policy Optimization, PPO), aim to stabilize learning through techniques like overestimation bias control and trust region enforcement. However, these approaches fail to address churn effectively. For instance, DoubleDQN suffers from greedy action deviations due to changes in value estimates, while PPO can silently violate its trust region due to policy churn. These existing methods overlook the compounded effect of churn between value and policy updates, resulting in reduced sample efficiency and poor performance, especially in large-scale decision-making tasks.
Researchers from Université de Montréal introduce Churn Approximated ReductIoN (CHAIN). This strategy specifically targets the reduction of value and policy churn by introducing regularization losses during training. CHAIN reduces the unwanted changes in network outputs for states not included in the current batch, effectively controlling churn across different DRL settings. By minimizing the churn effect, this method improves the stability of both value-based and policy-based RL algorithms. The innovation lies in the method’s simplicity and its ability to be easily integrated into most existing DRL algorithms with minimal code modifications. The ability to control churn leads to more stable learning and better sample efficiency across a variety of RL environments.
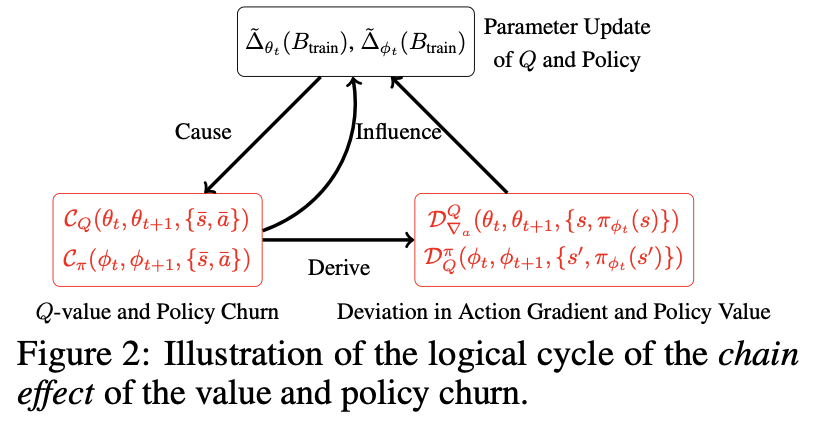
The CHAIN method introduces two main regularization terms: the value churn reduction loss (L_QC) and the policy churn reduction loss (L_PC). These terms are computed using a reference batch of data and reduce changes in the Q-network’s value outputs and policy network’s action outputs, respectively. This reduction is achieved by comparing current outputs with those from the previous iteration of the network. The method is evaluated using multiple DRL benchmarks, including MinAtar, OpenAI MuJoCo, DeepMind Control Suite, and offline datasets such as D4RL. The regularization is designed to be lightweight and is applied alongside the standard loss functions used in DRL training, making it highly versatile for a wide range of algorithms, including DoubleDQN, PPO, and SAC.
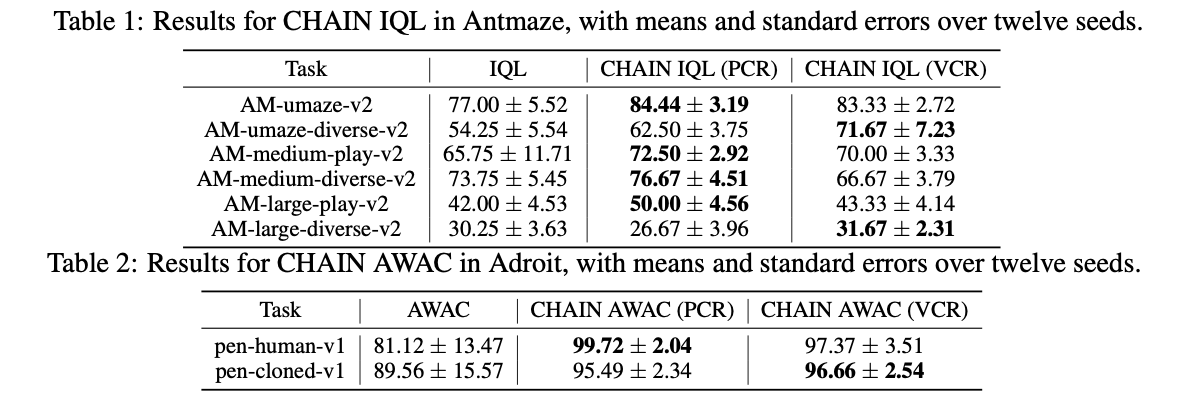
CHAIN showed significant improvements in both reducing churn and enhancing learning performance across various RL environments. In tasks like MinAtar’s Breakout, integrating CHAIN with DoubleDQN led to a marked reduction in value churn, resulting in improved sample efficiency and better overall performance compared to baseline methods. Similarly, in continuous control environments such as MuJoCo’s Ant-v4 and HalfCheetah-v4, applying CHAIN to PPO improved stability and final returns, outperforming standard PPO configurations. These findings demonstrate that CHAIN enhances the stability of training dynamics, leading to more reliable and efficient learning across a range of reinforcement learning scenarios, with consistent performance gains in both online and offline RL settings.
The CHAIN method addresses a fundamental challenge in DRL by reducing the destabilizing effect of churn. By controlling both value and policy churn, the approach ensures more stable updates during training, leading to improved sample efficiency and better final performance across various RL tasks. CHAIN’s ability to be easily incorporated into existing algorithms, with minimal modifications makes it a practical solution to a critical problem in reinforcement learning. This innovation has the potential to significantly improve the robustness and scalability of DRL systems, particularly in real-world, large-scale environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
