Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. Often, LLMs need to interact with other software, databases, or APIs to accomplish complex tasks. For example, an administrative chatbot that schedules meetings would require access to employees’ calendars and email. With access to tools, LLM agents can become more powerful—at the cost of additional complexity.
In this post, we introduce LLM agents and demonstrate how to build and deploy an e-commerce LLM agent using Amazon SageMaker JumpStart and AWS Lambda. The agent will use tools to provide new capabilities, such as answering questions about returns (“Is my return rtn001 processed?”) and providing updates about orders (“Could you tell me if order 123456 has shipped?”). These new capabilities require LLMs to fetch data from multiple data sources (orders, returns) and perform retrieval augmented generation (RAG).
To power the LLM agent, we use a Flan-UL2 model deployed as a SageMaker endpoint and use data retrieval tools built with AWS Lambda. The agent can subsequently be integrated with Amazon Lex and used as a chatbot inside websites or AWS Connect. We conclude the post with items to consider before deploying LLM agents to production. For a fully managed experience for building LLM agents, AWS also provides the agents for Amazon Bedrock feature (in preview).
A brief overview of LLM agent architectures
LLM agents are programs that use LLMs to decide when and how to use tools as necessary to complete complex tasks. With tools and task planning abilities, LLM agents can interact with outside systems and overcome traditional limitations of LLMs, such as knowledge cutoffs, hallucinations, and imprecise calculations. Tools can take a variety of forms, such as API calls, Python functions, or webhook-based plugins. For example, an LLM can use a “retrieval plugin” to fetch relevant context and perform RAG.
So what does it mean for an LLM to pick tools and plan tasks? There are numerous approaches (such as ReAct, MRKL, Toolformer, HuggingGPT, and Transformer Agents) to using LLMs with tools, and advancements are happening rapidly. But one simple way is to prompt an LLM with a list of tools and ask it to determine 1) if a tool is needed to satisfy the user query, and if so, 2) select the appropriate tool. Such a prompt typically looks like the following example and may include few-shot examples to improve the LLM’s reliability in picking the right tool.
More complex approaches involve using a specialized LLM that can directly decode “API calls” or “tool use,” such as GorillaLLM. Such finetuned LLMs are trained on API specification datasets to recognize and predict API calls based on instruction. Often, these LLMs require some metadata about available tools (descriptions, yaml, or JSON schema for their input parameters) in order to output tool invocations. This approach is taken by agents for Amazon Bedrock and OpenAI function calls. Note that LLMs generally need to be sufficiently large and complex in order to show tool selection ability.
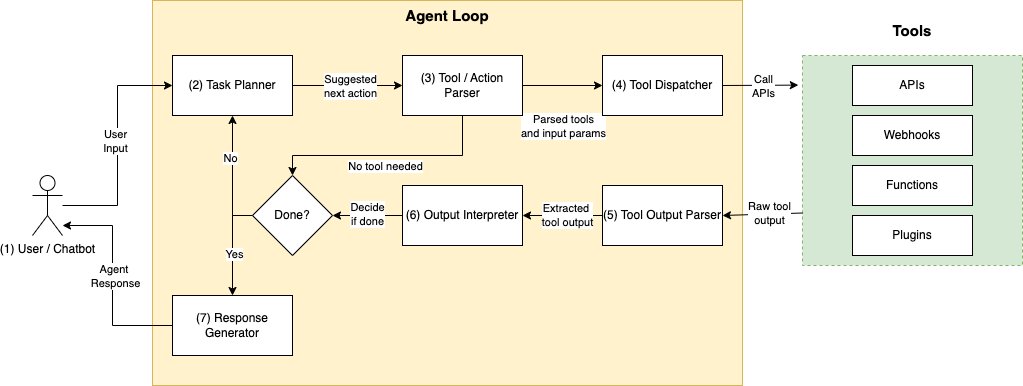
Assuming task planning and tool selection mechanisms are chosen, a typical LLM agent program works in the following sequence:
- User request – The program takes a user input such as “Where is my order
123456?” from some client application. - Plan next action(s) and select tool(s) to use – Next, the program uses a prompt to have the LLM generate the next action, for example, “Look up the orders table using
OrdersAPI.” The LLM is prompted to suggest a tool name such asOrdersAPIfrom a predefined list of available tools and their descriptions. Alternatively, the LLM could be instructed to directly generate an API call with input parameters such asOrdersAPI(12345).- Note that the next action may or may not involve using a tool or API. If not, the LLM would respond to user input without incorporating additional context from tools or simply return a canned response such as, “I cannot answer this question.”
- Parse tool request – Next, we need to parse out and validate the tool/action prediction suggested by the LLM. Validation is needed to ensure tool names, APIs, and request parameters aren’t hallucinated and that the tools are properly invoked according to specification. This parsing may require a separate LLM call.
- Invoke tool – Once valid tool name(s) and parameter(s) are ensured, we invoke the tool. This could be an HTTP request, function call, and so on.
- Parse output – The response from the tool may need additional processing. For example, an API call may result in a long JSON response, where only a subset of fields are of interest to the LLM. Extracting information in a clean, standardized format can help the LLM interpret the result more reliably.
- Interpret output – Given the output from the tool, the LLM is prompted again to make sense of it and decide whether it can generate the final answer back to the user or whether additional actions are required.
- Terminate or continue to step 2 – Either return a final answer or a default answer in the case of errors or timeouts.
Different agent frameworks execute the previous program flow differently. For example, ReAct combines tool selection and final answer generation into a single prompt, as opposed to using separate prompts for tool selection and answer generation. Also, this logic can be run in a single pass or run in a while statement (the “agent loop”), which terminates when the final answer is generated, an exception is thrown, or timeout occurs. What remains constant is that agents use the LLM as the centerpiece to orchestrate planning and tool invocations until the task terminates. Next, we show how to implement a simple agent loop using AWS services.
Solution overview
For this blog post, we implement an e-commerce support LLM agent that provides two functionalities powered by tools:
- Return status retrieval tool – Answer questions about the status of returns such as, “What is happening to my return
rtn001?” - Order status retrieval tool – Track the status of orders such as, “What’s the status of my order
123456?”
The agent effectively uses the LLM as a query router. Given a query (“What is the status of order 123456?”), select the appropriate retrieval tool to query across multiple data sources (that is, returns and orders). We accomplish query routing by having the LLM pick among multiple retrieval tools, which are responsible for interacting with a data source and fetching context. This extends the simple RAG pattern, which assumes a single data source.
Both retrieval tools are Lambda functions that take an id (orderId or returnId) as input, fetches a JSON object from the data source, and converts the JSON into a human friendly representation string that’s suitable to be used by LLM. The data source in a real-world scenario could be a highly scalable NoSQL database such as DynamoDB, but this solution employs simple Python Dict with sample data for demo purposes.
Additional functionalities can be added to the agent by adding Retrieval Tools and modifying prompts accordingly. This agent can be tested a standalone service that integrates with any UI over HTTP, which can be done easily with Amazon Lex.
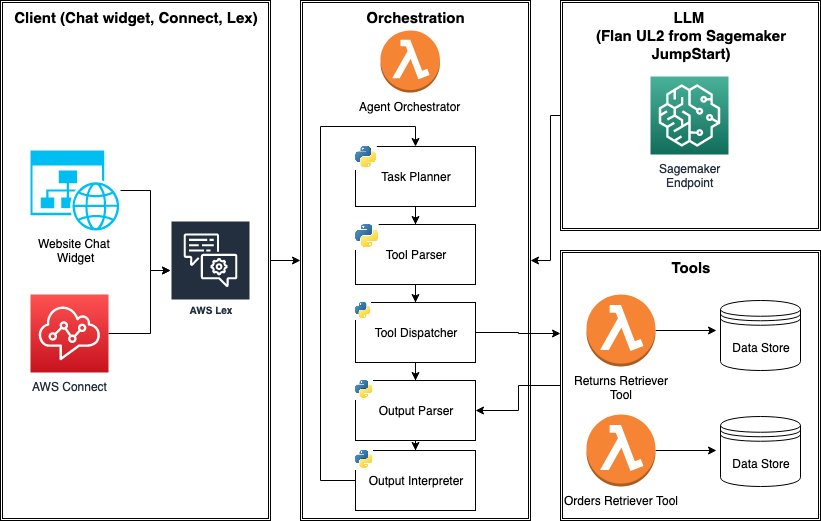
Here are some additional details about the key components:
- LLM inference endpoint – The core of an agent program is an LLM. We will use SageMaker JumpStart foundation model hub to easily deploy the
Flan-UL2model. SageMaker JumpStart makes it easy to deploy LLM inference endpoints to dedicated SageMaker instances. - Agent orchestrator – Agent orchestrator orchestrates the interactions among the LLM, tools, and the client app. For our solution, we use an AWS Lambda function to drive this flow and employ the following as helper functions.
- Task (tool) planner – Task planner uses the LLM to suggest one of 1) returns inquiry, 2) order inquiry, or 3) no tool. We use prompt engineering only and
Flan-UL2model as-is without fine-tuning. - Tool parser – Tool parser ensures that the tool suggestion from task planner is valid. Notably, we ensure that a single
orderIdorreturnIdcan be parsed. Otherwise, we respond with a default message. - Tool dispatcher – Tool dispatcher invokes tools (Lambda functions) using the valid parameters.
- Output parser – Output parser cleans and extracts relevant items from JSON into a human-readable string. This task is done both by each retrieval tool as well as within the orchestrator.
- Output interpreter – Output interpreter’s responsibility is to 1) interpret the output from tool invocation and 2) determine whether the user request can be satisfied or additional steps are needed. If the latter, a final response is generated separately and returned to the user.
- Task (tool) planner – Task planner uses the LLM to suggest one of 1) returns inquiry, 2) order inquiry, or 3) no tool. We use prompt engineering only and
Now, let’s dive a bit deeper into the key components: agent orchestrator, task planner, and tool dispatcher.
Agent orchestrator
Below is an abbreviated version of the agent loop inside the agent orchestrator Lambda function. The loop uses helper functions such as task_planner or tool_parser, to modularize the tasks. The loop here is designed to run at most two times to prevent the LLM from being stuck in a loop unnecessarily long.
Task planner (tool prediction)
The agent orchestrator uses task planner to predict a retrieval tool based on user input. For our LLM agent, we will simply use prompt engineering and few shot prompting to teach the LLM this task in context. More sophisticated agents could use a fine-tuned LLM for tool prediction, which is beyond the scope of this post. The prompt is as follows:
Tool dispatcher
The tool dispatch mechanism works via if/else logic to call appropriate Lambda functions depending on the tool’s name. The following is tool_dispatch helper function’s implementation. It’s used inside the agent loop and returns the raw response from the tool Lambda function, which is then cleaned by an output_parser function.
Deploy the solution
Important prerequisites – To get started with the deployment, you need to fulfill the following prerequisites:
- Access to the AWS Management Console via a user who can launch AWS CloudFormation stacks
- Familiarity with navigating the AWS Lambda and Amazon Lex consoles
Flan-UL2requires a singleml.g5.12xlargefor deployment, which may necessitate increasing resource limits via a support ticket. In our example, we useus-east-1as the Region, so please make sure to increase the service quota (if needed) inus-east-1.
Deploy using CloudFormation – You can deploy the solution to us-east-1 by clicking the button below:![]()
Deploying the solution will take about 20 minutes and will create a LLMAgentStack stack, which:
- deploys the SageMaker endpoint using
Flan-UL2model from SageMaker JumpStart; - deploys three Lambda functions:
LLMAgentOrchestrator,LLMAgentReturnsTool,LLMAgentOrdersTool; and - deploys an AWS Lex bot that can be used to test the agent:
Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot.
Test the solution
The stack deploys an Amazon Lex bot with the name Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot. The bot can be used to test the agent end-to-end. Here’s an additional comprehensive guide for testing AWS Amazon Lex bots with a Lambda integration and how the integration works at a high level. But in short, Amazon Lex bot is a resource that provides a quick UI to chat with the LLM agent running inside a Lambda function that we built (LLMAgentOrchestrator).
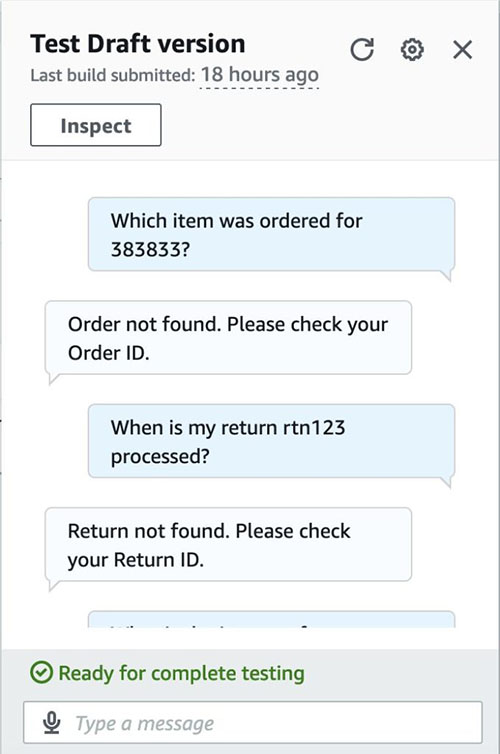
The sample test cases to consider are as follows:
- Valid order inquiry (for example, “Which item was ordered for
123456?”)- Order “123456” is a valid order, so we should expect a reasonable answer (e.g. “Herbal Handsoap”)
- Valid return inquiry for a return (for example, “When is my return
rtn003processed?”)- We should expect a reasonable answer about the return’s status.
- Irrelevant to both returns or orders (for example, “How is the weather in Scotland right now?”)
- An irrelevant question to returns or orders, thus a default answer should be returned (“Sorry, I cannot answer that question.”)
- Invalid order inquiry (for example, “Which item was ordered for
383833?”)- The id 383832 does not exist in the orders dataset and hence we should fail gracefully (for example, “Order not found. Please check your Order ID.”)
- Invalid return inquiry (for example, “When is my return
rtn123processed?”)- Similarly, id
rtn123does not exist in the returns dataset, and hence should fail gracefully.
- Similarly, id
- Irrelevant return inquiry (for example, “What is the impact of return
rtn001on world peace?”)- This question, while it seems to pertain to a valid order, is irrelevant. The LLM is used to filter questions with irrelevant context.
To run these tests yourself, here are the instructions.
- On the Amazon Lex console (AWS Console > Amazon Lex), navigate to the bot entitled
Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot. This bot has already been configured to call theLLMAgentOrchestratorLambda function whenever theFallbackIntentis triggered. - In the navigation pane, choose Intents.
- Choose Build at the top right corner
- 4. Wait for the build process to complete. When it’s done, you get a success message, as shown in the following screenshot.

- Test the bot by entering the test cases.
Cleanup
To avoid additional charges, delete the resources created by our solution by following these steps:
- On the AWS CloudFormation console, select the stack named
LLMAgentStack(or the custom name you picked). - Choose Delete
- Check that the stack is deleted from the CloudFormation console.
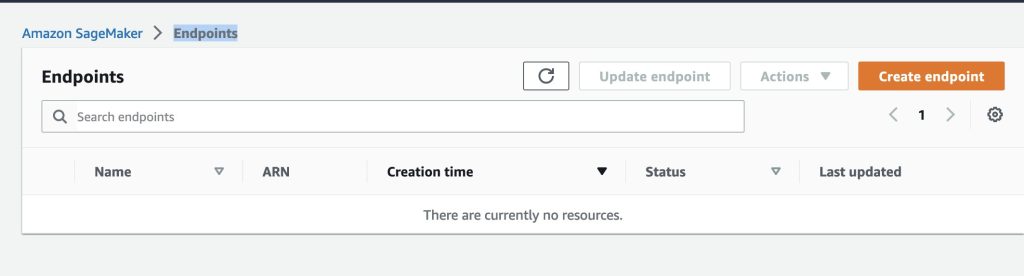
Important: double-check that the stack is successfully deleted by ensuring that the Flan-UL2 inference endpoint is removed.
- To check, go to AWS console > Sagemaker > Endpoints > Inference page.
- The page should list all active endpoints.
- Make sure
sm-jumpstart-flan-bot-endpointdoes not exist like the below screenshot.
Considerations for production
Deploying LLM agents to production requires taking extra steps to ensure reliability, performance, and maintainability. Here are some considerations prior to deploying agents in production:
- Selecting the LLM model to power the agent loop: For the solution discussed in this post, we used a
Flan-UL2model without fine-tuning to perform task planning or tool selection. In practice, using an LLM that is fine-tuned to directly output tool or API requests can increase reliability and performance, as well as simplify development. We could fine-tune an LLM on tool selection tasks or use a model that directly decodes tool tokens like Toolformer.- Using fine-tuned models can also simplify adding, removing, and updating tools available to an agent. With prompt-only based approaches, updating tools requires modifying every prompt inside the agent orchestrator, such as those for task planning, tool parsing, and tool dispatch. This can be cumbersome, and the performance may degrade if too many tools are provided in context to the LLM.
- Reliability and performance: LLM agents can be unreliable, especially for complex tasks that cannot be completed within a few loops. Adding output validations, retries, structuring outputs from LLMs into JSON or yaml, and enforcing timeouts to provide escape hatches for LLMs stuck in loops can enhance reliability.
Conclusion
In this post, we explored how to build an LLM agent that can utilize multiple tools from the ground up, using low-level prompt engineering, AWS Lambda functions, and SageMaker JumpStart as building blocks. We discussed the architecture of LLM agents and the agent loop in detail. The concepts and solution architecture introduced in this blog post may be appropriate for agents that use a small number of a predefined set of tools. We also discussed several strategies for using agents in production. Agents for Bedrock, which is in preview, also provides a managed experience for building agents with native support for agentic tool invocations.
About the Author
 John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds B.S. in computer science from Stanford University.
John Hwang is a Generative AI Architect at AWS with special focus on Large Language Model (LLM) applications, vector databases, and generative AI product strategy. He is passionate about helping companies with AI/ML product development, and the future of LLM agents and co-pilots. Prior to joining AWS, he was a Product Manager at Alexa, where he helped bring conversational AI to mobile devices, as well as a derivatives trader at Morgan Stanley. He holds B.S. in computer science from Stanford University.
