In the quest for Artificial General Intelligence, LLMs and LMMs stand as remarkable tools, akin to brilliant minds, capable of diverse human-like tasks. While benchmarks are crucial for assessing their capabilities, the landscape is fragmented, with datasets scattered across platforms like Google Drive and Dropbox. lm-evaluation-harness sets a precedent for LLM evaluation, yet multimodal model evaluation lacks a unified framework. This gap highlights the infancy of multi-modality model evaluation, calling for a cohesive approach to assess their performance across various datasets.
Researchers from Nanyang Technological University, University of Wisconsin-Madison, and Bytedance have developed LLaVA-NeXT, a pioneering open-source LMM trained solely on text-image data. The innovative AnyRes technique enhances reasoning, Optical Character Recognition (OCR), and world knowledge, showcasing exceptional performance across various image-based multimodal tasks. Surpassing Gemini-Pro on benchmarks like MMMU and MathVista, LLaVA-NeXT signifies a significant leap in multimodal understanding capabilities.
Venturing into video comprehension, LLaVA-NeXT unexpectedly exhibits robust performance, featuring key enhancements. Leveraging AnyRes, it achieves zero-shot video representation, displaying unprecedented modality transfer ability for LMMs. The model’s length generalization capability effectively handles longer videos, surpassing token length constraints through linear scaling techniques. Further, supervised fine-tuning (SFT) and direct preference optimization (DPO) enhance the video understanding prowess. At the same time, efficient deployment via SGLang enables 5x faster inference, facilitating scalable applications like million-level video re-captioning. LLaVA-NeXT’s feats underscore its state-of-the-art performance and versatility across multimodal tasks, rivaling proprietary models like Gemini-Pro on key benchmarks.
The AnyRes algorithm in LLaVA-NeXT is a flexible framework that efficiently processes high-resolution images. It segments images into sub-images using different grid configurations to achieve optimal performance while meeting the token length constraints of the underlying LLM architecture. With adjustments, it can also be used for video processing, but token allocation per frame needs to be carefully considered to avoid exceeding token limits. Spatial pooling techniques optimize token distribution, balancing frame count and token density. However, effectively capturing comprehensive video content remains challenging when increasing the frame count.
Addressing the need to process longer video sequences, LLaVA-NeXT implements length generalization techniques inspired by recent advancements in handling long sequences in LLMs. The model can accommodate longer sequences by scaling the maximum token length capacity, enhancing its applicability in analyzing extended video content, and employing DPO leverages LLM-generated feedback to train LLaVA-NeXT-Video, resulting in substantial performance gains. This approach offers a cost-effective alternative to acquiring human preference data and showcases promising prospects for refining training methodologies in multimodal contexts.
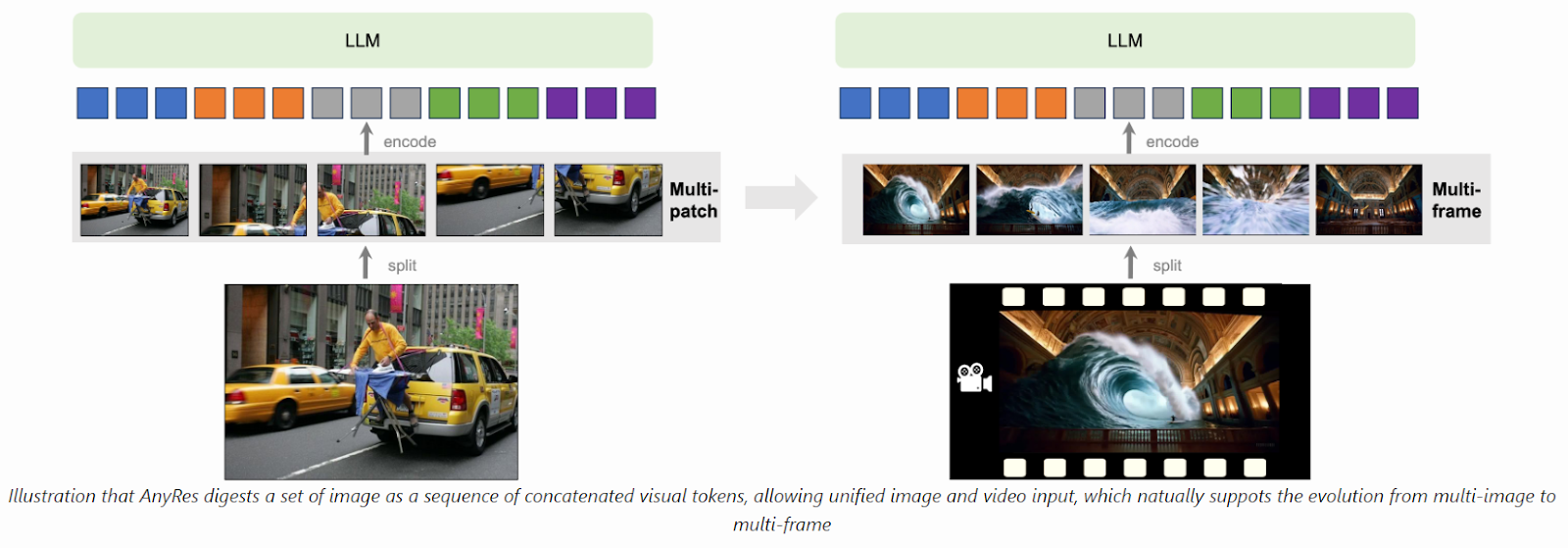
In conclusion, To effectively represent videos within the constraints of the LLM, the researchers found an optimal configuration: allocating 12×12 tokens per frame, sampling 16 frames per video, and leveraging “linear scaling” techniques to further Fine-tuningilities, allowing for longer sequences of inference tokens. Fine-tuning LLaVA-NeXT-Video involves a mixed training approach with video and image data. Mixing data types within batches yields the best performance, highlighting the significance of incorporating image and video data during training to enhance the model’s proficiency in video-related tasks.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
