In recent years, the field of computer vision has witnessed remarkable progress, pushing the boundaries of how machines interpret complex visual information. One pivotal challenge in this domain is precisely interpreting intricate image details, which demands a nuanced understanding of global and local visual cues. Traditional models, including Convolutional Neural Networks (CNNs) and Vision Transformers, have significantly progressed. Yet, they often need to work effectively to balance the detailed local content with the broader image context, an essential aspect for tasks requiring fine-grained visual discrimination.
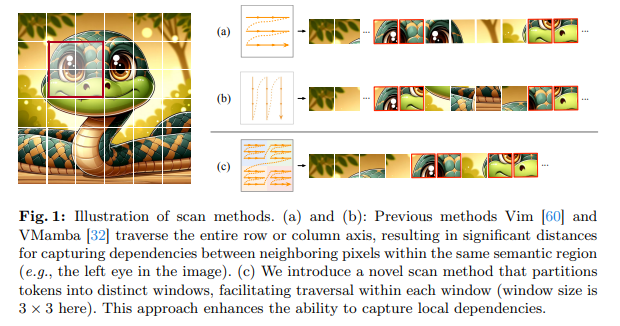
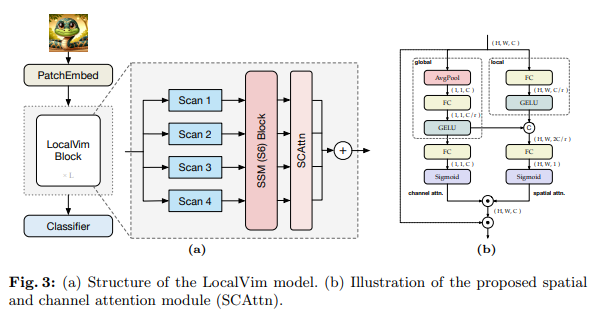
Researchers from SenseTime Research, The University of Sydney, and the University of Science and Technology of China presented LocalMamba, which was designed to refine visual data processing. By adopting a unique scanning strategy that divides images into distinct windows, LocalMamba allows for a more focused examination of local details while maintaining an awareness of the image’s overall structure. This strategic division enables the model to navigate through the complexities of visual data more efficiently, ensuring that both broad and minute details are captured with equal precision.
LocalMamba’s innovative methodology extends beyond traditional scanning techniques by integrating a dynamic scanning direction search. This search optimizes the model’s focus, allowing it to highlight crucial features within each window adaptively. Such adaptability ensures that LocalMamba understands the intricate relationships between image elements, setting it apart from conventional methods. The superiority of LocalMamba is underscored through rigorous testing across various benchmarks, where it demonstrates marked performance improvements.LocalMamba significantly surpasses existing models in image classification tasks, showcasing its ability to deliver nuanced and comprehensive image analysis.
LocalMamba’s versatility is evident across a spectrum of practical applications, from object detection to semantic segmentation. In each of these areas, LocalMamba sets new standards of accuracy and efficiency. Its success harmonizes the capture of local image features with a global understanding. This balance is crucial for applications requiring detailed recognition capabilities, such as autonomous driving, medical imaging, and content-based image retrieval.
LocalMamba’s approach opens up new avenues for future research in visual state space models, highlighting the untapped potential of optimizing scanning directions. By effectively leveraging local scanning within distinct windows, LocalMamba enhances the model’s capacity to interpret visual data, offering insights into how machines can better mimic human visual perception. This breakthrough suggests new avenues for exploration in the quest to develop more intelligent and capable visual processing systems.
In conclusion, LocalMamba marks a significant leap forward in the evolution of computer vision models. Its core innovation lies in the ability to intricately analyze visual data by emphasizing local details without compromising the global context. This dual focus ensures a comprehensive understanding of images, facilitating superior performance across various tasks. The research team’s contributions extend beyond the immediate benefits of improved accuracy and efficiency. They offer a blueprint for future advancements in the field, demonstrating the critical role of scanning mechanisms in enhancing the capabilities of visual processing models. LocalMamba sets new benchmarks in computer vision and inspires continued innovation toward more intelligent and wise machine vision systems.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Discord Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel and 38k+ ML SubReddit
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
