Text-to-image (T2I) generation is a rapidly evolving field within computer vision and artificial intelligence. It involves creating visual images from textual descriptions blending natural language processing and graphic visualization domains. This interdisciplinary approach has significant implications for various applications, including digital art, design, and virtual reality.
Various methods have been proposed for controllable text-to-image generation, including ControlNet, layout-to-image methods, and image editing. Large language models (LLMs) like GPT-4 and Llama have capabilities in natural language processing and are being adopted as agents for complex tasks. However, they must improve when dealing with complex scenarios involving multiple objects and their intricate relationships. This limitation highlights the need for a more sophisticated approach to accurately interpreting and visualizing elaborate textual descriptions.
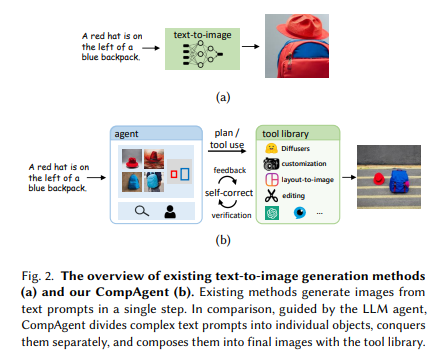
Researchers from Tsinghua University, the University of Hong Kong, and Noah’s Ark Lab introduced CompAgent. This method leverages an LLM agent for compositional text-to-image generation. CompAgent stands out by adopting a divide-and-conquer strategy, enhancing image synthesis controllability for complex text prompts.
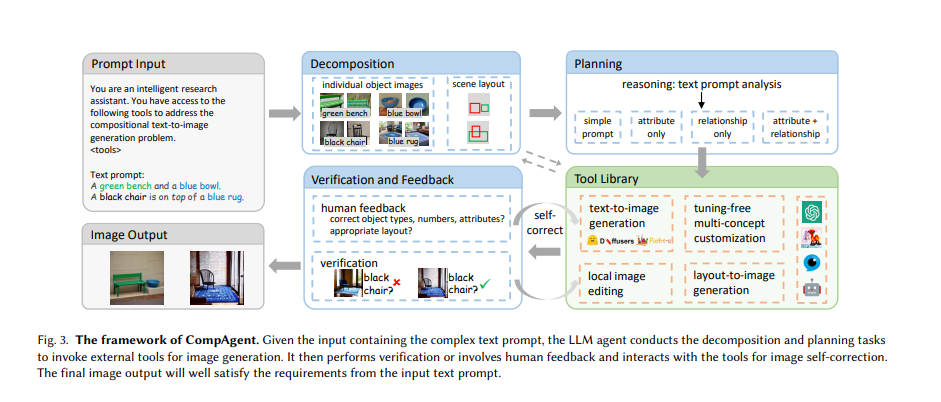
CompAgent utilizes a tuning-free multi-concept customization tool to generate images based on existing object images and input prompts, a layout-to-image generation tool to manage object relationships within a scene, and a local image editing tool for precise attribute correction using segmentation masks and cross-attention editing. The agent selects the most suitable tool based on the text prompt’s attributes and relationships. Verification and feedback, including human input, are integral for ensuring attribute correctness and adjusting scene layouts. This comprehensive approach, combining multiple tools and verification processes, enhances the capability of text-to-image generation, guaranteeing accurate and contextually relevant image outputs.

CompAgent has shown exceptional performance in generating images that accurately represent complex text prompts. It achieves a 48.63% 3-in-1 metric, surpassing previous methods by more than 7%. It has reached over 10% improvement in compositional text-to-image generation on T2I-CompBench, a benchmark for open-world compositional text-to-image generation. This success illustrates CompAgent’s ability to effectively address the challenges of object type, quantity, attribute binding, and relationship representation in image generation.
In conclusion, CompAgent represents a significant achievement in text-to-image generation. It solves the problem of generating images from complex text prompts and opens new avenues for creative and practical applications. Its ability to accurately render multiple objects with their attributes and relationships in a single image is a testament to the advancements in AI-driven image synthesis. It addresses existing challenges in the field and paves the way for new possibilities in digital imagery and AI integration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
