Graph Transformers need help with scalability in graph sequence modeling due to high computational costs, and existing attention sparsification methods fail to adequately address data-dependent contexts. State space models (SSMs) like Mamba are effective and efficient in modeling long-range dependencies in sequential data, but adapting them to non-sequential graph data is challenging. Many sequence models do not improve with increasing context length, indicating the need for alternative approaches to capture long-range dependencies.
Graph modeling advancements have been driven by Graph Neural Networks (GNNs) like GCN, GraphSage, and GAT, which address long-range graph dependencies. Yet, their scalability is challenged by the high computational costs of Graph Transformer models. To overcome this, alternatives like BigBird, Performer, and Exphormer introduce sparse attention and graph-specific subsampling, significantly reducing computational demands while maintaining effectiveness. These innovations mark a pivotal shift towards more efficient graph modeling techniques, showcasing the field’s evolution towards addressing scalability and efficiency.
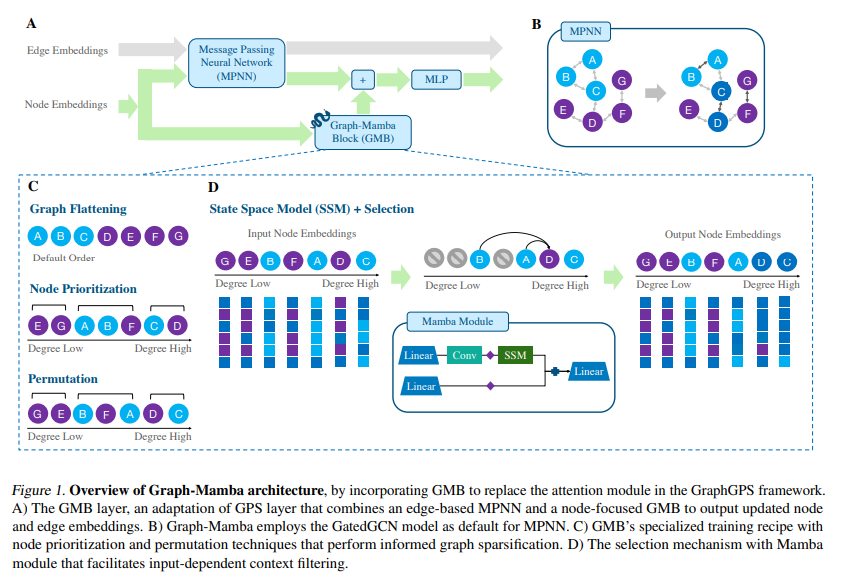
A team of researchers has introduced Graph-Mamba, an innovative model integrating a selective SSM into the GraphGPS framework. It presents an efficient solution to input-dependent graph sparsification challenges. The creative Graph-Mamba block (GMB) achieves advanced sparsification by combining a Mamba module’s selection mechanism with a node prioritization approach, ensuring linear-time complexity. This positions Graph-Mamba as a formidable alternative to traditional dense graph attention, promising significant improvements in computational efficiency and scalability.
Graph-Mamba’s implementation adaptively selects relevant context information and prioritizes crucial nodes, utilizing SSMs and the GatedGCN model for nuanced context-aware sparsification. Evaluated across ten diverse datasets, including image classification, synthetic graph datasets, and 3D molecular structures, Graph-Mamba demonstrates superior performance and efficiency. Thanks to its innovative permutation and node prioritization strategies, it outperforms sparse attention methods and rivals dense attention Transformers, which are now recommended as standard training and inference practices.
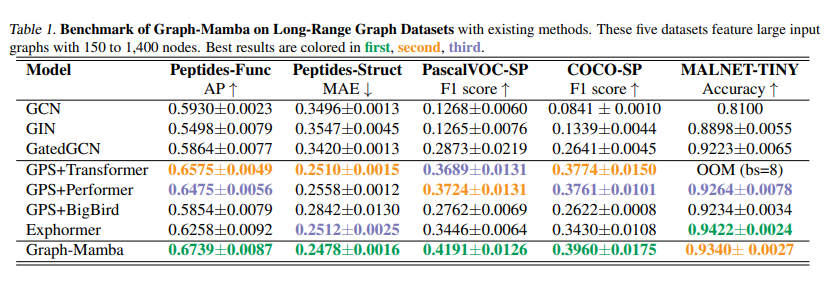
Experiments conducted on GNN and LRGB benchmarks validate its efficacy, showcasing Graph-Mamba’s ability to handle various graph sizes and complexities with reduced computational demands. Remarkably, it achieves these results with substantially lower computational costs, exemplified by a 74% reduction in GPU memory consumption and a 66% reduction in FLOPs on the Peptides-func dataset. These results highlight Graph-Mamba’s ability to manage long-range dependencies efficiently, setting a new standard in the field.
Graph-Mamba marks a significant advancement in graph modeling, tackling the long-standing challenge of long-range dependency recognition with a novel, efficient solution. Its introduction broadens the scope of possible analyses within various fields and opens up new avenues for research and application. By combining SSMs’ strengths with graph-specific innovations, Graph-Mamba stands as a transformative development, poised to reshape the future of computational graph analysis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
