Autoregressive LLMs are complex neural networks that generate coherent and contextually relevant text through sequential prediction. These LLms excel at handling large datasets and are very strong at translation, summarization, and conversational AI. However, achieving high quality in vision generation often comes at the cost of increased computational demands, especially for higher resolutions or longer videos. Despite efficient learning with compressed latent spaces, video diffusion models are limited to fixed-length outputs and lack contextual adaptability in autoregressive models like GPT.
Current autoregressive video generation models face many limitations. Diffusion models make excellent text-to-image and text-to-video tasks but rely on fixed-length tokens, which limits their versatility and scalability in video generations. Autoregressive models typically suffer from vector quantization issues because they transform visual data into discrete-valued token spaces. Higher-quality tokens require more tokens, while using these tokens increases the computational cost. While advancements like VAR and MAR improve image quality and generative modeling, their application to video generation remains constrained by inefficiencies in modeling and challenges in adapting to multi-context scenarios.
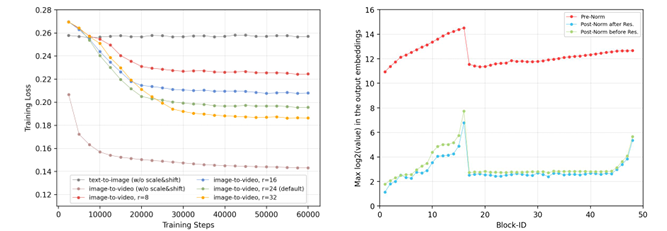
To address these issues, researchers from BUPT, ICT-CAS, DLUT, and BAAI proposed NOVA, a non-quantized autoregressive model for video generation. NOVA approaches video generation by predicting frames sequentially over time and spatial token sets within each frame in a flexible order. This model combines time-based and space-based prediction by separating how frames and spatial sets are generated. It uses a pre-trained language model to process text prompts and optical flow to track motion. For time-based prediction, the model applies a block-wise causal masking method, while for space-based prediction, it uses a bidirectional approach to predict sets of tokens. The model introduces scaling and shifting layers to improve stability and uses sine-cosine embeddings for better positioning. It also adds diffusion loss to help predict token probabilities in a continuous space, making training and inference more efficient and improving video quality and scalability.

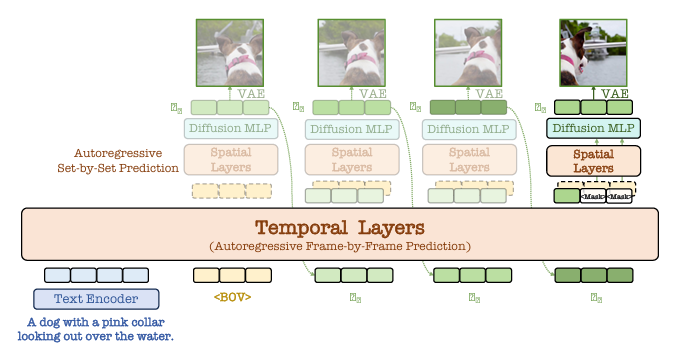
The researchers trained NOVA using high-quality datasets, starting with 16 million image-text pairs from sources like DataComp, COYO, Unsplash, and JourneyDB, which were later expanded to 600 million pairs from LAION, DataComp, and COYO. For text-to-video, researchers used 19 million video-text pairs from Panda–70M and other internal datasets, plus 1 million pairs from Pexels-a caption engine based on Emu2-17B generated descriptions. NOVA’s architecture included a spatial AR layer, a denoising MLP block, and a 16-layer encoder-decoder structure for handling spatial and temporal components. The temporal encoder-decoder dimensions ranged from 768 to 1536, and the denoising MLP had three blocks with 1280 dimensions. A pre-trained VAE model captured image features using masking and diffusion schedulers. NOVA was trained on sixteen A100 nodes with the AdamW optimizer. It was first trained for text-to-image tasks and then for text-to-video tasks.
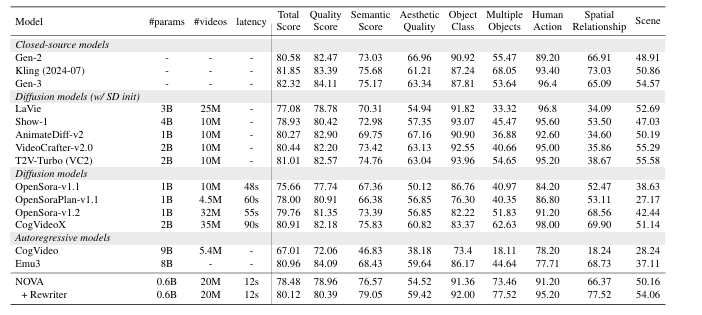
Results from evaluations on T2I-CompBench, GenEval, and DPG-Bench showed that NOVA outperformed models like PixArt-α and SD v1/v2 in text-to-image and text-to-video generation tasks. NOVA generated higher-quality images and videos with clearer, more detailed visuals. It also provided more accurate results and better matched the text inputs and the generated outputs.

In summary, the proposed NOVA model significantly advances text-to-image and text-to-video generation. The method reduces computational complexity and improves efficiency by integrating temporal frame-by-frame and spatial set-by-set predictions with good-quality outputs. Its performance exceeds existing models, with near-commercial image quality and video fidelity. This work provides a foundation for future research, offering a baseline for developing scalable models and real-time video generation and opening up new possibilities for advancements in the field.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
