Artificial intelligence has recently expanded its role in areas that handle highly sensitive information, such as healthcare, education, and personal development, through advanced language models (LLMs) like ChatGPT. These models, often proprietary, can process large datasets and deliver impressive results. However, this capability raises significant privacy concerns because user interactions may unintentionally reveal personally identifiable information (PII) during model responses. Traditional approaches have focused on sanitizing the data used to train these models, but this does not prevent privacy leaks during real-time use. There is a critical need for solutions that protect sensitive information without sacrificing model performance, ensuring privacy and security while still meeting the high standards users expect.
A central issue in the LLM field is maintaining privacy without compromising the accuracy and utility of responses. Proprietary LLMs often deliver the best results due to extensive data and training but may expose sensitive information through unintentional PII leaks. Open-source models, hosted locally, offer a safer alternative by limiting external access, yet they generally need more sophistication and quality than proprietary models. This gap between privacy and performance complicates efforts to securely integrate LLMs into areas handling sensitive data, such as medical consultations or job applications. As LLMs continue to be integrated into more sensitive applications, balancing these concerns is essential to ensure privacy without undermining the capabilities of these AI tools.
Current safeguards for user data include anonymizing inputs before sending them to external servers. While this method enhances security by masking sensitive details, it often comes at the cost of response quality, as the model loses essential context that may be critical for accurate responses. For instance, anonymizing specific details in a job application email could limit the model’s ability to tailor the response effectively. Such limitations highlight the need for innovative approaches beyond simple redaction to maintain privacy without impairing the user experience. Thus, despite progress in privacy-preserving methods, the trade-off between security and utility remains a significant challenge for LLM developers.
Researchers from Columbia University, Stanford University, and Databricks introduced PrivAcy Preservation from Internet-based and Local Language MOdel ENsembles (PAPILLON), a novel privacy-preserving pipeline designed to integrate the strengths of both local open-source models and high-performance proprietary models. PAPILLON operates under a concept called “Privacy-Conscious Delegation,” where a regional model, trusted for its privacy, acts as an intermediary between the user and the proprietary model. This intermediary filters sensitive information before sending any request to the external model, ensuring that private data remains secure while allowing access to high-quality responses only available from advanced proprietary systems.
The PAPILLON system is structured to protect user privacy while maintaining response quality using prompt optimization techniques. The pipeline is multi-staged, first processing user queries with a local model to selectively redact or mask sensitive information. If the query requires more complex handling, the proprietary model is engaged, but only with minimal exposure to PII. PAPILLON achieves this through customized prompts that direct the proprietary model while concealing personal data. This method allows PAPILLON to generate responses of similar quality to those from proprietary models but with an added layer of privacy protection. Additionally, PAPILLON’s design is modular, which means it can adapt to various local and proprietary model combinations, depending on the task’s privacy and quality needs.
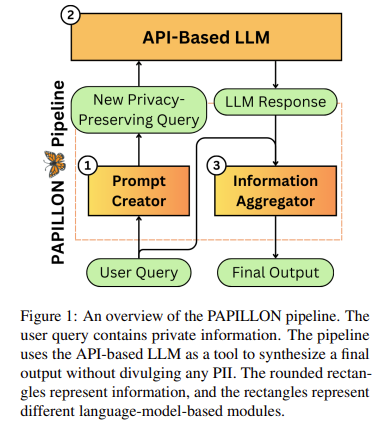
The researchers tested PAPILLON’s effectiveness using the Private User Prompt Annotations (PUPA) benchmark dataset, which includes 901 real-world user queries containing PII. In its best configuration, PAPILLON employed the Llama-3.18B-Instruct model locally and the GPT-4o-mini model for proprietary tasks. The optimized pipeline achieved an 85.5% response quality rate, closely mirroring the accuracy of proprietary models while keeping privacy leakage to just 7.5%. This performance is particularly promising compared to current redaction-only approaches, which often see notable drops in response quality. Moreover, different configurations were tested to determine the best balance of performance and privacy, revealing that models like Llama-3.1-8B achieved high quality and low leakage, proving effective even for privacy-sensitive tasks.
The results from PAPILLON suggest that balancing high-quality responses with low privacy risk in LLMs is possible. The system’s design allows it to leverage both the privacy-conscious processing of local models and the robust capabilities of proprietary models, making it a suitable choice for applications where privacy and accuracy are essential. PAPILLON’s modular structure also makes it adaptable to different LLM configurations, enhancing its flexibility for diverse tasks. For example, the system retained high-quality response accuracy across various LLM setups without significant privacy compromise, showcasing its potential for broader implementation in privacy-sensitive AI applications.

Key Takeaways from the Research:
- High Quality with Low Privacy Leakage: PAPILLON achieved an 85.5% response quality rate while limiting privacy leakage to 7.5%, indicating an effective balance between performance and security.
- Flexible Model Use: PAPILLON’s design allows it to operate effectively with open-source and proprietary models. It has successfully tested Llama-3.1-8B and GPT-4o-mini configurations.
- Adaptability: The pipeline’s modular structure makes it adaptable for various LLM combinations, broadening its applicability in diverse sectors requiring privacy protection.
- Improved Privacy Standards: Unlike simple redaction methods, PAPILLON retains context to maintain response quality, proving more effective than traditional anonymization approaches.
- Future Potential: The research provides a framework for further improvements in privacy-conscious AI models, highlighting the need for continued advancements in secure, adaptable LLM technology.

In conclusion, PAPILLON offers a promising path forward for integrating privacy-conscious techniques in AI. Converting the gap between privacy and quality allows sensitive applications to utilize AI without risking user data. This approach shows that privacy-conscious delegation and prompt optimization can meet the growing demand for secure, high-quality AI models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
