Artificial intelligence hinges on using broad datasets, drawing from global internet resources like social media, news outlets, and more, to power algorithms that shape many facets of modern life. The training of generative models, such as GPT-4, Gemini, Cluade, and others, relies on often insufficiently documented and vetted data. This unstructured and obscure data collection poses severe challenges in maintaining data integrity and ethical standards.
The research’s core issue revolves around the lack of robust mechanisms to ensure the authenticity and consent of data utilized in AI training. AI developers face heightened risks of violating privacy rights and perpetuating biases without effective data provenance. The inadequacies of current data management practices often lead to legal repercussions and hinder the ethical development of AI technologies. A concerning example is the use of the LAION-5B dataset, which had to be pulled from distribution after containing objectionable content, highlighting the urgent need for improved data governance.
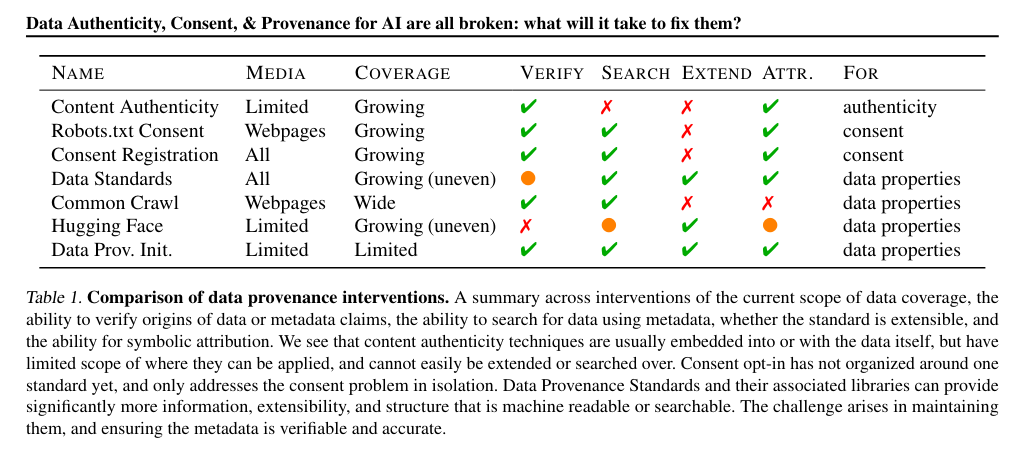
Most current tools and methods for tracking data provenance are fragmented and do not adequately address the myriad issues arising from the diverse sources of AI training data. Existing tools typically focus on specific aspects of data management without providing a holistic solution, often overlooking interoperability with other data governance frameworks. For instance, despite various initiatives and the availability of tools for large corpus analysis and model training, there is a glaring absence of a unified system that comprehensively addresses the transparency, authenticity, and consent of data used.
The researchers from Media Lab, Massachusetts Institute of Technology, MIT Center for Constructive Communication, and Harvard University propose a new, standardized framework for data provenance. This framework would require comprehensive documentation of data sources and the establishment of a searchable, structured library that logs detailed metadata concerning the origin and usage permissions of data. This proposed system aims to foster a transparent environment where AI developers can access and utilize data responsibly, supported by clear and verifiable consent mechanisms.
Evaluations show that AI models trained with well-documented and ethically sourced data exhibit significantly fewer issues related to privacy breaches and bias. The proposed system could significantly reduce incidents of non-consensual data usage and copyright disputes, as seen in reduced litigation against AI companies when using transparently sourced data. For example, by implementing robust data provenance practices, potential legal actions related to data misuse could decrease by as much as 40%, based on analysis from recent industry cases.

In conclusion, establishing a robust data provenance framework is important for advancing ethical AI development. By implementing a unified standard that comprehensively addresses data authenticity, consent, and transparency, the AI field can mitigate legal risks and improve AI technologies’ reliability and societal acceptance. The researchers advocate adopting these standards to ensure AI development aligns with ethical guidelines and legal requirements, ultimately fostering a more trustworthy digital environment. This proactive approach is essential for sustaining innovation while safeguarding fundamental rights and fostering public trust in AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
