In artificial intelligence (AI), utilizing monolithic large language models (LLMs) such as GPT-4 has been pivotal in advancing modern generative AI applications. However, the maintenance, training, and deployment of these LLMs at scale are fraught with challenges, primarily due to the high costs and complexities involved. These challenges are exacerbated by a growing disproportion in the compute-to-memory ratio within contemporary AI accelerators, leading to a bottleneck known as the “memory wall.” This bottleneck necessitates innovative deployment strategies to make AI more accessible and feasible.
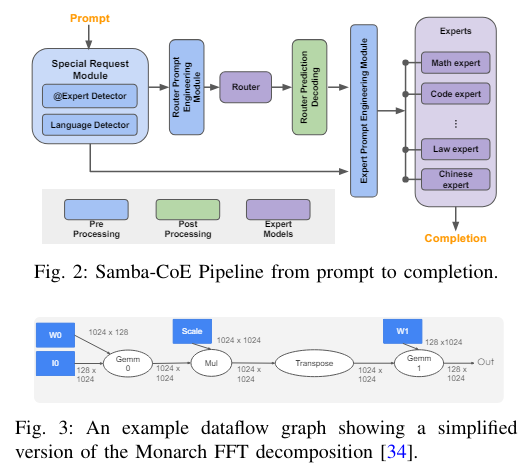
The Composition of Experts (CoE) approach offers a promising solution to these challenges. By integrating many smaller, specialized models, each with significantly fewer parameters than monolithic LLMs, CoE can match or surpass the performance of larger models. This modular strategy substantially reduces the complexity and cost of training and deploying AI systems. However, CoE implementations face their own set of challenges on conventional hardware platforms. These include the reduced operational intensity of smaller models, which can complicate achieving high utilization, and the logistical and financial burdens of hosting and dynamically switching among many models.
Researchers from SambaNova Systems, Inc., are exploring an innovative application of CoE by deploying the Samba-CoE system on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU). This commercial dataflow accelerator has been co-designed specifically for enterprise-level inference and training applications and features a groundbreaking three-tier memory system. This system comprises on-chip distributed SRAM, on-package High-Bandwidth Memory (HBM), and off-package DDR DRAM, which enhance the operational efficiency of AI models.
A crucial component of this architecture is the dedicated inter-RDU network, which facilitates scaling up and out across multiple sockets. This capability is critical for supporting the CoE framework, which relies on the seamless integration and communication between numerous small expert models. The effectiveness of this setup is demonstrated through substantial performance gains in various benchmarks. For instance, the Samba-CoE system achieves speedups ranging from 2x to 13x compared to an unfused baseline when running on eight RDU sockets.
The practical benefits of deploying CoE on the SambaNova platform are evident in the significant reductions in the physical footprint and the operational overhead of AI systems. Specifically, the 8-socket RDU Node reduces the machine footprint by up to 19x and improves model switching times by 15x to 31x. Regarding overall speedup, the system outperforms the DGX H100 and DGX A100 by 3.7x and 6.6x, respectively.

In conclusion, while CoE is not a novel concept introduced in this research, its application within the SambaNova SN40L platform demonstrates a significant advancement in AI technology deployment. This implementation mitigates the memory wall challenge and democratizes advanced AI capabilities, making them accessible to a broader range of users and applications. Through this innovative approach, the research contributes to the ongoing evolution of AI infrastructure, paving the way for more sustainable and economically viable AI deployments across various industries.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
