Retrieval Augmented Generation (RAG) is a method that enhances the capabilities of Large Language Models (LLMs) by integrating a document retrieval system. This integration allows LLMs to fetch relevant information from external sources, thereby improving the accuracy and relevance of the responses generated. This approach addresses the limitations of traditional LLMs, such as the need for extensive training and the risk of providing outdated or incorrect information. RAG’s key advantage lies in its ability to ground the model’s output in reliable sources, thus reducing hallucinations and ensuring up-to-date knowledge without requiring expensive ongoing training.
A significant challenge in RAG is handling queries requiring multiple documents with diverse content. Such queries are common in various industries but pose a difficulty because the required documents may have vastly different embeddings, making it hard to retrieve all relevant information accurately. This problem necessitates a solution that can efficiently fetch and combine information from multiple sources. In complex scenarios, like chemical plant accidents, retrieving data from documents related to various aspects such as equipment maintenance, weather conditions, and worker management is essential to provide comprehensive answers.
Existing RAG solutions typically use embeddings from the last-layer decoder block of a Transformer model to retrieve documents. However, this method needs to adequately address multi-aspect queries, as it struggles with retrieving documents that cover significantly different content aspects. Some current techniques include RAPTOR, Self-RAG, and Chain-of-Note, which focus on improving retrieval accuracy but fail to handle complex, multi-aspect queries effectively. These methods aim to refine the relevance of retrieved data but need help to handle the diversity in document content required for multi-faceted queries.
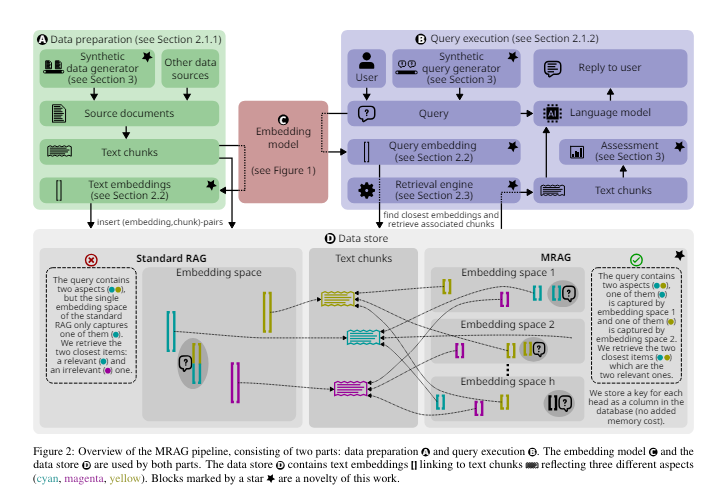
Researchers from ETH Zurich, Cledar, BASF SE and Warsaw University of Technology have introduced Multi-Head RAG (MRAG) to solve the problem of multi-aspect queries. This novel scheme leverages the activations from the multi-head attention layer of Transformer models instead of the last-layer decoder activations. The research team designed MRAG to utilize different attention heads to capture various data aspects, improving the retrieval accuracy for complex queries. By harnessing the multi-head attention mechanism, MRAG creates embeddings representing different facets of the data, enhancing the system’s ability to fetch relevant information across diverse content areas.
The key innovation in MRAG is the use of activations from multiple attention heads to create embeddings. Each attention head in a Transformer model can learn to capture different data aspects, resulting in embeddings that represent various facets of data items and queries. This method enables MRAG to handle multi-aspect queries more effectively without increasing the space requirements compared to standard RAG. In practical terms, MRAG constructs embeddings during the data preparation stage by using activations from the multi-head attention layer. During query execution, these multi-aspect embeddings allow the retrieval of relevant text chunks from different embedding spaces, addressing the complexity of multi-aspect queries.
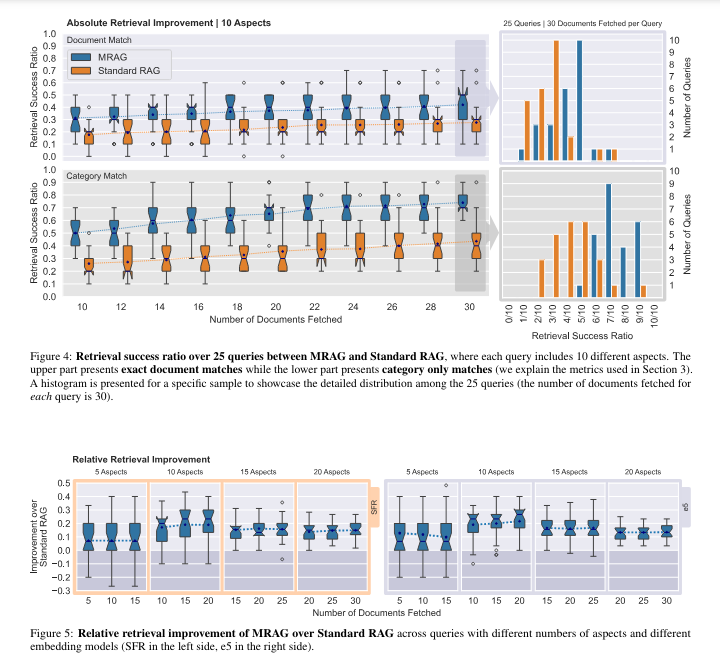
MRAG significantly improves retrieval relevance, showing up to 20% better performance than standard RAG baselines in fetching multi-aspect documents. The evaluation used synthetic datasets and real-world use cases, proving MRAG’s effectiveness across different scenarios. For instance, in a test involving multi-aspect Wikipedia articles, MRAG achieved a 20% improvement in relevance over standard RAG baselines. Furthermore, MRAG’s performance in real-world tasks such as legal document synthesis and chemical plant accident analysis showcased its practical benefits. In the legal document synthesis task, MRAG’s ability to retrieve contextually relevant documents from various legal frameworks was particularly praiseworthy.
Moreover, MRAG’s advantages extend beyond retrieval accuracy. The method is cost-effective and energy-efficient, not requiring additional LLM queries, multiple model instances, increased storage, or multiple inference passes over the embedding model. This efficiency, combined with enhanced retrieval accuracy, positions MRAG as a valuable advancement in the LLMs and RAG systems field. MRAG can seamlessly integrate with existing RAG frameworks and benchmarking tools, offering a versatile and scalable solution for complex document retrieval needs.
In conclusion, the introduction of MRAG marks a significant advancement in the field of RAG, addressing the challenges posed by multi-aspect queries. By leveraging the multi-head attention mechanism of Transformer models, MRAG offers a more accurate and efficient solution for complex document retrieval needs. This innovation paves the way for more reliable and relevant outputs from LLMs, benefiting various industries that require comprehensive data retrieval capabilities. Researchers have successfully demonstrated MRAG’s potential, highlighting its effectiveness and efficiency in improving the relevance of retrieved documents.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
