The quest for augmenting the decision-making prowess of machines has led to innovative strides, particularly in reinforcement learning (RL). This technique, pivotal for the autonomy of algorithms, empowers them to discern optimal choices through a meticulous process of trial and error, navigating the intricacies of various environments. At this juncture, the focal point of interest is enhancing large language models (LLMs), propelling them beyond mere response generation to mastering multi-turn decision-making tasks. This leap necessitates a nuanced approach, as conventional RL methodologies falter, primarily constrained by their myopic focus on immediate rewards rather than a coherent sequence of actions required for intricate interactions.
Actor–Critic Framework with a Hierarchical Structure (ArCHer) is an innovative framework developed by researchers from the University of California Berkeley and Google DeepMind, marking a pivotal turn in addressing the above challenge. The essence of ArCHer lies in its unique dual-level reinforcement learning strategy, intricately woven to optimize both macro strategies and micro decisions. By segregating decision-making into hierarchical layers, ArCHer meticulously navigates through the complexities of sequential decisions, ensuring that each action taken by the LLM is locally optimal and aligned with the overarching goal.
The underlying architecture of ArCHer is a testament to the synergy between hierarchical reinforcement learning and the vast potential of LLMs. At its core, ArCHer employs a high-level algorithm tasked with overarching strategy formulation, while a lower-level counterpart focuses on executing immediate actions. This bifurcation allows for unprecedented precision and foresight in multi-turn tasks, bridging the gap between short-term actions and long-term objectives.
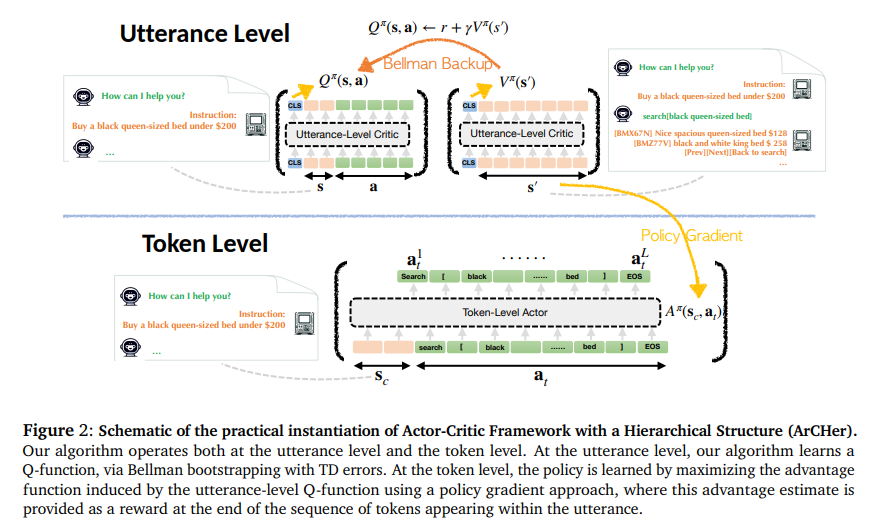
The framework introduces a novel actor-critic structure, wherein the high-level critic assesses the potential of various strategies, aggregating rewards over multiple turns. Simultaneously, the low-level actor refines individual actions within each turn, guided by the strategic insights from its high-level counterpart. This dynamic interplay ensures a robust and flexible approach to decision-making, capable of adapting to the evolving demands of complex interactions.
Empirical evidence underscores the efficacy of ArCHer, with the framework showcasing significant advancements in efficiency and performance across various test environments. One of the hallmark achievements of ArCHer is its remarkable sample efficiency, outperforming existing on-policy methods by approximately 100-fold. The framework demonstrates an impressive ability to scale with model size, indicating a promising avenue for deploying even more capable and sophisticated AI agents.
ArCHer’s impact extends to the broader landscape of AI and machine learning. The research enriches the theoretical understanding of reinforcement learning applications by pioneering a solution to the intricate challenge of multi-turn decision-making in LLMs. It paves the way for developing more adept and versatile AI systems. These systems, equipped with the strategic depth and decision-making acumen offered by ArCHer, hold the potential to revolutionize a wide array of fields, from automated customer service to complex problem-solving in dynamic environments.
In conclusion, ArCHer embodies a significant leap forward in the quest to enhance the decision-making capabilities of artificial intelligence. Through its innovative hierarchical approach, ArCHer addresses the pressing challenge of multi-turn interactions and sets a new benchmark for applying reinforcement learning in LLMs. The possibilities for the future of AI appear both boundless and bright, heralding an era of machines capable of navigating the world’s complexities with unprecedented finesse and intelligence.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
