In an era where digital privacy has become paramount, the ability of artificial intelligence (AI) systems to forget specific data upon request is not just a technical challenge but a societal imperative. The researchers have embarked on an innovative journey to tackle this issue, particularly within image-to-image (I2I) generative models. These models, known for their prowess in crafting detailed images from given inputs, have presented unique challenges for data deletion, primarily due to their deep learning nature, which inherently remembers training data.
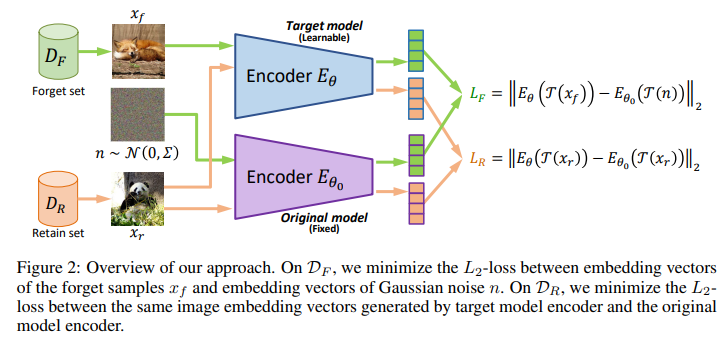
The crux of the research lies in developing a machine unlearning framework specifically designed for I2I generative models. Unlike previous attempts focusing on classification tasks, this framework aims to remove unwanted data efficiently – termed forget samples – while preserving the desired data’s quality and integrity or retaining samples. This endeavor is not trivial; generative models, by design, excel in memorizing and reproducing input data, making selective forgetting a complex task.

The researchers from The University of Texas at Austin and JPMorgan proposed an algorithm grounded in a unique optimization problem to address this. Through theoretical analysis, they established a solution that effectively removes forgotten samples with minimal impact on the retained samples. This balance is crucial for adhering to privacy regulations without sacrificing the model’s overall performance. The algorithm’s efficacy was demonstrated through rigorous empirical studies on two substantial datasets, ImageNet1K and Places-365, showcasing its ability to comply with data retention policies without needing direct access to the retained samples.
This pioneering work marks a significant advancement in machine unlearning for generative models. It offers a viable solution to a problem that is as much about ethics and legality as technology. The framework’s ability to efficiently erase specific data sets from memory without a complete model retraining represents a leap forward in developing privacy-compliant AI systems. By ensuring that the integrity of the retained data remains intact while eliminating the information of the forgotten samples, the research provides a robust foundation for the responsible use and management of AI technologies.
In essence, the research undertaken by the team from The University of Texas at Austin and JPMorgan Chase stands as a testament to the evolving landscape of AI, where technological innovation meets the growing demands for privacy and data protection. The study’s contributions can be summarized as follows:
- It pioneers a framework for machine unlearning within I2I generative models, addressing a gap in the current research landscape.
- Through a novel algorithm, it achieves the dual objectives of retaining data integrity and completely removing forgotten samples, balancing performance with privacy compliance.
- The research’s empirical validation on large-scale datasets confirms the framework’s effectiveness, setting a new standard for privacy-aware AI development.
As AI grows, the need for models that respect user privacy and comply with legal standards has never been more critical. This research not only addresses this need but also opens up new avenues for future exploration in the realm of machine unlearning, marking a significant step towards developing powerful and privacy-conscious AI technologies.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
