Model merging is an advanced technique in machine learning aimed at combining the strengths of multiple expert models into a single, more powerful model. This process allows the system to benefit from the knowledge of various models while reducing the need for large-scale individual model training. Merging models cuts down computational and storage costs and improves the model’s ability to generalize to different tasks. By merging, developers can leverage decentralized development, where different teams build expert models independently, which are combined for a stronger overall system.
A significant challenge is the scalability of model merging. Most studies have focused on small-scale models with limited expert models being merged, typically two or three. As models grow in size and the number of expert models increases, the complexity of merging becomes greater. The key issue is how to efficiently merge larger models without sacrificing performance. Another concern is how factors like the base model quality—whether the base model is pre-trained or fine-tuned for specific tasks—impact the merged model’s performance. Understanding these factors is critical as the community develops increasingly large and complex models.
Current methods for model merging include simple techniques like averaging the weights of expert models and more sophisticated ones such as task arithmetic, where task-specific parameters are adjusted. However, these methods have been tested only on small models, generally less than 7 billion parameters, and usually involve merging just a few models. While these methods have shown some success, their effectiveness in larger-scale models has not been systematically evaluated. Moreover, the ability of these methods to generalize to unseen tasks remains underexplored, especially when dealing with multiple large-scale models.
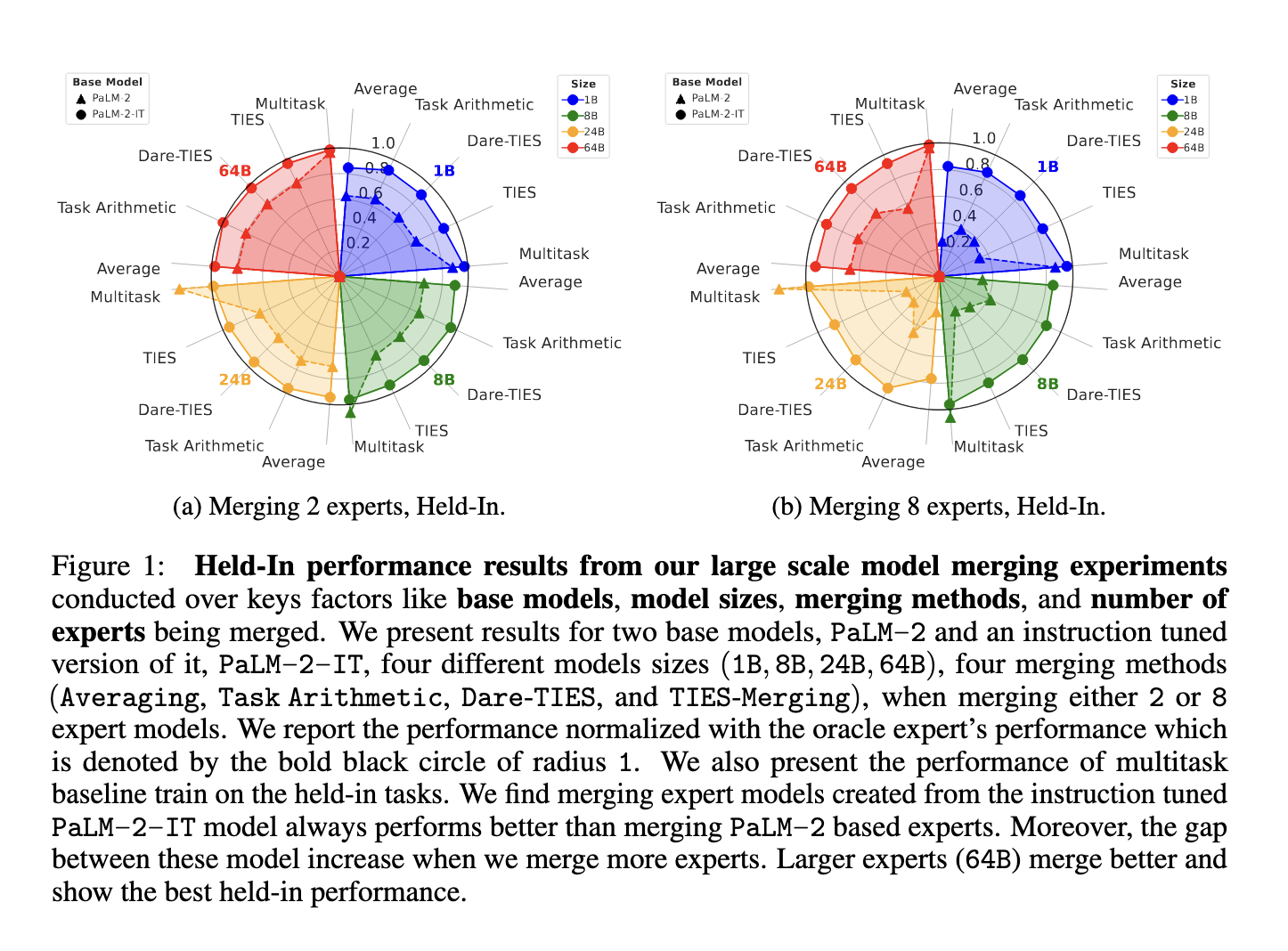
A research team from The University of North Carolina at Chapel Hill, Google, and Virginia Tech introduced a comprehensive study evaluating model merging on a large scale. The researchers explored merging models that range from 1 billion to 64 billion parameters, using up to eight expert models in various configurations. Four merging methods were evaluated: Averaging, Task Arithmetic, Dare-TIES, and TIES-Merging. They also experimented with two base models, PaLM-2 and PaLM-2-IT (the instruction-tuned version of PaLM-2). Their goal was to examine how factors like base model quality, model size, and the number of experts being merged impact the overall effectiveness of the merged model. This large-scale evaluation is one of the first attempts to assess model merging at this scale systematically.
The researchers used fully fine-tuned expert models trained on specific tasks in their methodology. These were then merged to evaluate their performance on held-in tasks (tasks the experts were trained on) and held-out tasks (unseen tasks for zero-shot generalization). The merging techniques involved modifying task-specific parameters or using simple averaging to combine the models. PaLM-2-IT, the instruction-tuned variant of the base model, was used as a reference point to see if instruction-tuning improved the model’s ability to generalize after merging. This methodology allowed for a systematic analysis of the impact of model size, number of experts, and base model quality on merging success.
The study’s results revealed several important insights. First, they found larger models, such as those with 64 billion parameters, were easier to merge than smaller ones. Merging significantly improved the generalization capabilities of the models, particularly when using instruction-tuned models like PaLM-2-IT. For example, when merging eight large expert models, the merged models outperformed multitask-trained models, achieving higher performance on unseen tasks. Specifically, the results showed that merging models from PaLM-2-IT led to better zero-shot generalization than those from the pre-trained PaLM-2. Furthermore, the performance gap between different merging methods narrowed as the model size increased, meaning that even simple techniques like averaging could be effective for large models. The researchers also noted that merging more expert models, up to eight, resulted in better generalization without significant performance loss.

The performance metrics showed that larger and instruction-tuned models had a clear advantage. For instance, merging eight expert models from a 64-billion-parameter PaLM-2-IT model achieved results that surpassed those of a multitask training baseline, traditionally used for improving generalization. The study highlighted that the instruction-tuned models performed better in all evaluations, showing superior results in zero-shot generalization to unseen tasks. The merged models exhibited better adaptation to new tasks than individual fine-tuned experts.
In conclusion, the research team’s study demonstrates that model merging, especially at large scales, is a promising approach for creating highly generalizable language models. The findings suggest that instruction-tuned models significantly benefit the merging process, particularly in improving zero-shot performance. As models grow, merging methods like those evaluated in this study will become crucial for developing scalable and efficient systems that can generalize across diverse tasks. The study provides practical insights for practitioners and opens new avenues for further research into large-scale model merging techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
