Large language models (LLMs) are advancing the automation of computer code generation in artificial intelligence. These sophisticated models, trained on extensive datasets of programming languages, have shown remarkable proficiency in crafting code snippets from natural language instructions. Despite their prowess, aligning these models with the nuanced requirements of human programmers remains a significant hurdle. While effective to a degree, traditional methods often fall short when faced with complex, multi-faceted coding tasks, leading to outputs that, although syntactically correct, may only partially capture the intended functionality.
Enter StepCoder, an innovative reinforcement learning (RL) framework designed by research teams from Fudan NLPLab, Huazhong University of Science and Technology, and KTH Royal Institute of Technology to tackle the nuanced challenges of code generation. At its core, StepCoder aims to refine the code creation process, making it more aligned with human intent and significantly more efficient. The framework distinguishes itself through two main components: the Curriculum of Code Completion Subtasks (CCCS) and Fine-Grained Optimization (FGO). Together, these mechanisms address the twin challenges of exploration in the vast space of potential code solutions and the precise optimization of the code generation process.
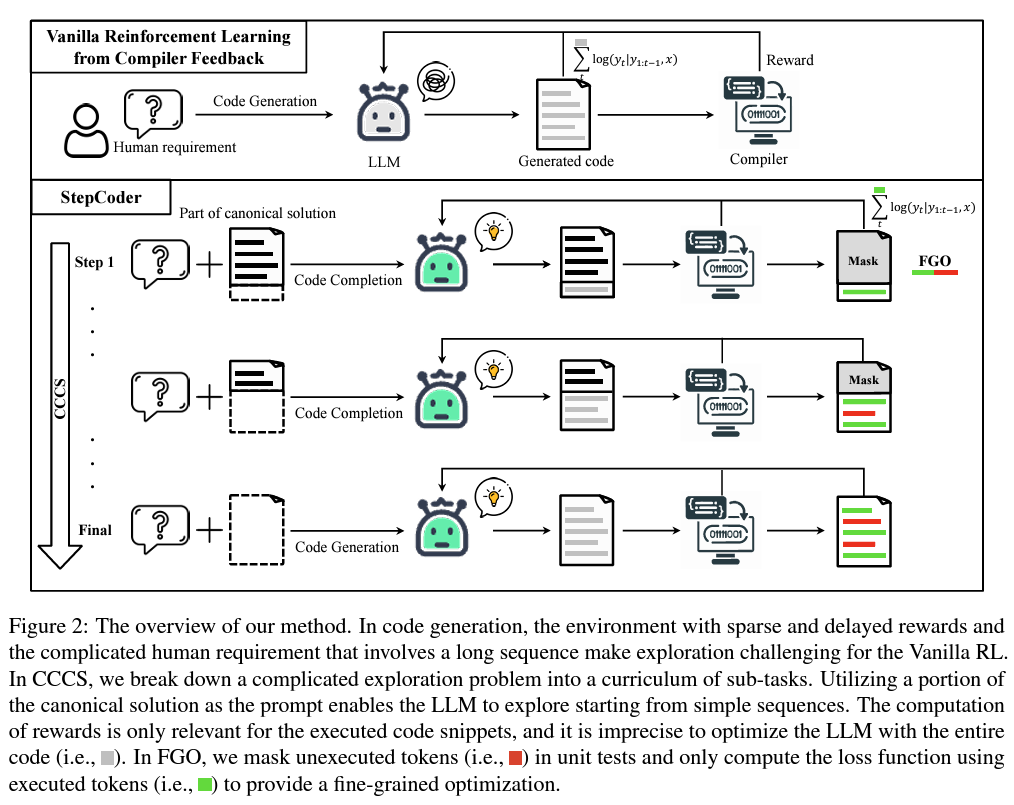
CCCS revolutionizes exploration by segmenting the daunting task of generating long code snippets into manageable subtasks. This systematic breakdown simplifies the model’s learning curve, enabling it to tackle increasingly complex coding requirements gradually with greater accuracy. As the model progresses, it navigates from completing simpler chunks of code to synthesizing entire programs based solely on human-provided prompts. This step-by-step escalation makes the exploration process more tractable and significantly enhances the model’s capability to generate functional code from abstract requirements.
The FGO component complements CCCS by honing in on the optimization process. It leverages a dynamic masking technique to focus the model’s learning on executed code segments, disregarding irrelevant portions. This targeted optimization ensures that the learning process is directly tied to the functional correctness of the code, as determined by the outcomes of unit tests. The result is a model that generates syntactically correct code and is functionally sound and more closely aligned with the programmer’s intentions.
The efficacy of StepCoder was rigorously tested against existing benchmarks, showcasing superior performance in generating code that met complex requirements. The framework’s ability to navigate the output space more efficiently and produce functionally accurate code sets a new standard in automated code generation. Its success lies in the technological innovation it represents and its approach to learning, which closely mirrors the incremental nature of human skill acquisition.
This research marks a significant milestone in bridging the gap between human programming intent and machine-generated code. StepCoder’s novel approach to tackling the challenges of code generation highlights the potential for reinforcement learning to transform how we interact with and leverage artificial intelligence in programming. As we move forward, the insights gleaned from this study offer a promising path toward more intuitive, efficient, and effective tools for code generation, paving the way for advancements that could redefine the landscape of software development and artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
