Research in computational linguistics continues to explore how large language models (LLMs) can be adapted to integrate new knowledge without compromising the integrity of existing information. A key challenge is ensuring that these models, fundamental to various language processing applications, maintain accuracy even as they expand their knowledge bases.
One conventional approach involves supervised fine-tuning, where LLMs are incrementally trained on data that aligns with or extends beyond their pre-training. While popular, this method has shown mixed results. The fine-tuning process involves presenting the model with examples it might partially recognize or not know, prompting it to adjust its responses accordingly. The effectiveness of these methods is typically evaluated by how these models maintain their performance when presented with data that either aligns with or extends their existing knowledge base.
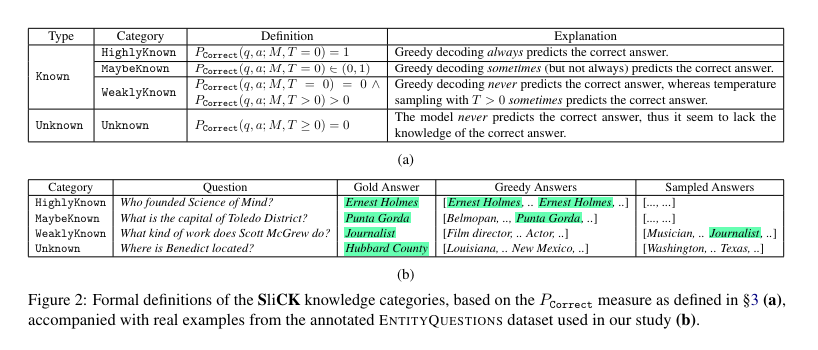
A research team from Technion – Israel Institute of Technology and Google Research has introduced SliCK, a novel framework specifically designed to examine integrating new knowledge within LLMs. This methodology stands out by categorizing knowledge into distinct levels, ranging from HighlyKnown to Unknown, providing a granular analysis of how different types of information affect model performance. This setup allows for a precise evaluation of the model’s ability to assimilate new facts while maintaining the accuracy of its existing knowledge base, highlighting the delicate balance required in model training.
In the methodology, the study leverages the PaLM model, a robust LLM developed by Google, which was fine-tuned using datasets carefully designed to include varying proportions of knowledge categories: HighlyKnown, MaybeKnown, WeaklyKnown, and Unknown. These datasets are derived from a curated subset of factual questions mapped from Wikidata relations, enabling a controlled examination of the model’s learning dynamics. The experiment meticulously quantifies the model’s performance across these categories using exact match (EM) metrics to assess how effectively the model integrates new information while avoiding the pitfalls of hallucinations. This structured approach provides a clear view of the impact of fine-tuning with both familiar and novel data on model accuracy.
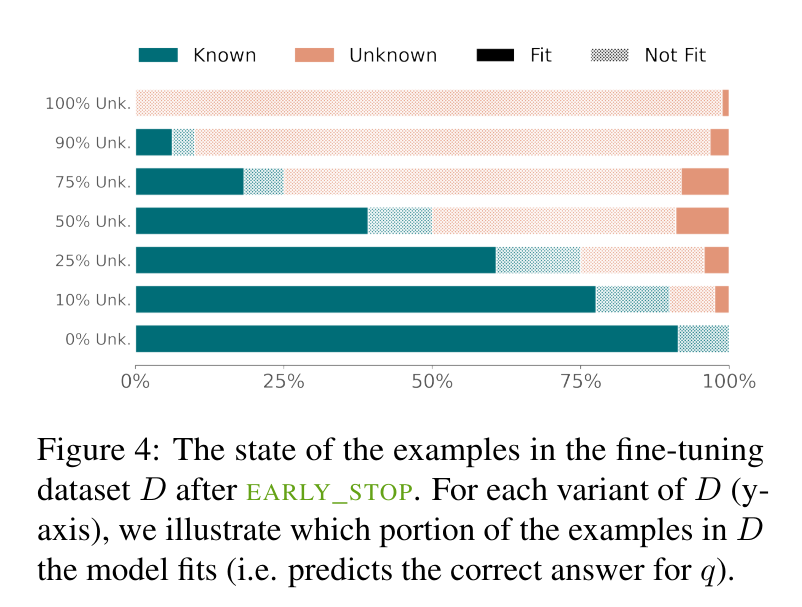
The study’s findings demonstrate the effectiveness of the SliCK categorization in enhancing the fine-tuning process. Models trained using this structured approach, particularly with a 50% Known and 50% Unknown mix, showed an optimized balance, achieving a 5% higher accuracy in generating correct responses compared to models trained with predominantly Unknown data. Conversely, when the proportion of Unknown data exceeded 70%, the models’ propensity for hallucinations increased by approximately 12%. These results highlight SliCK’s critical role in quantitatively assessing and managing the risk of error as new information is integrated during the fine-tuning of LLMs.
To summarize, the research by Technion – Israel Institute of Technology and Google Research thoroughly examines fine-tuning LLMs using the SliCK framework to manage the integration of new knowledge. The study highlights the delicate balance required in model training, with the PaLM model demonstrating improved accuracy and reduced hallucinations when trained under controlled knowledge conditions. These findings underscore the importance of strategic data categorization in enhancing model reliability and performance, offering valuable insights for future developments in machine learning methodologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
