The digital realm is perpetually on the cusp of innovation, with 3D content creation being one of its most dynamic frontiers. Critical to numerous sectors such as gaming, film production, and virtual reality, this sphere has seen a transformative shift with the advent of automatic 3D generation technologies. These technologies are revolutionizing how we conceive and interact with digital environments and democratizing 3D content creation, making it accessible to creators with varying levels of expertise.
Central to the challenge of advancing 3D content creation is the quest for methodologies that can produce detailed and complex 3D objects swiftly. While effective, previous techniques often needed to be improved when balancing detail with time efficiency. Creating a high-fidelity 3D model was a laborious process that demanded considerable computational resources and time, usually resulting in models that, despite the effort, needed more detail.
A breakthrough came from researchers at Tsinghua University and ShengShu, who applied video diffusion models in 3D generation and introduced V3D. This approach has set a new benchmark for creating intricate 3D models. By conceptualizing the generation of multi-view images of an object as a continuous video sequence, V3D leverages the complex dynamics of video diffusion to produce 3D models with unprecedented detail and fidelity in record time.
The V3D framework operates on a nuanced understanding of video diffusion, integrating geometrical consistency into the model to ensure that the generated multi-view images can be seamlessly reconstructed into coherent 3D models. This method allows for rapidly creating high-quality 3D meshes or Gaussian models, significantly reducing the time required for 3D model generation from hours to minutes.
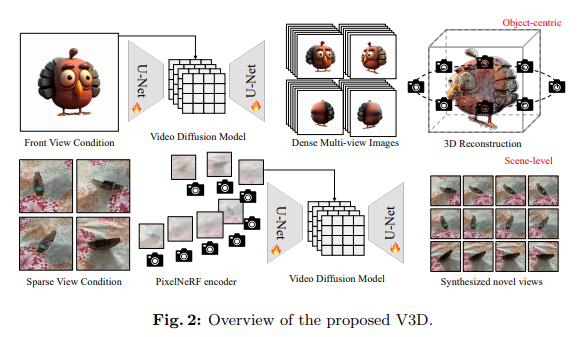
V3D’s efficacy in transforming 3D content creation is underscored by its remarkable performance across various benchmarks. Not only does it excel in generating detailed 3D objects, but it also extends its capabilities to scene-level novel view synthesis. This allows for creating images from new viewpoints with exceptional consistency and detail, showcasing the model’s versatility and potential to enhance digital experiences.

Reflecting on V3D’s capabilities and achievements, its impact on 3D content creation is undeniable. The model represents a leap forward in overcoming the traditional challenges associated with 3D generation, offering a faster, more efficient, and detail-oriented approach to model creation. Its success heralds a new era of possibilities in digital content creation, promising to fuel further innovations and applications across various industries.
In conclusion, key aspects of V3D include the following:
- 3D content creation by enabling the rapid production of detailed 3D models.
- Video diffusion models to generate multi-view images as a video sequence for 3D model creation.
- Geometrical consistency to ensure coherent reconstruction of 3D models from generated images.
- High-quality 3D meshes or Gaussians in a significantly reduced time frame, moving from hours to minutes.
- Versatility through its application in object-centric generation and scene-level view synthesis, enhancing digital experiences with detailed and consistent imaging.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
