Computer vision researchers often focus on training powerful encoder networks for self-supervised learning (SSL) methods. These encoders generate image representations, but researchers frequently ignore the predictive part of the model after pretraining despite its potential to contain valuable information. This research explores a different approach, drawing inspiration from reinforcement learning: instead of discarding the predictive model, researchers investigate if it can be reused for various downstream vision tasks.
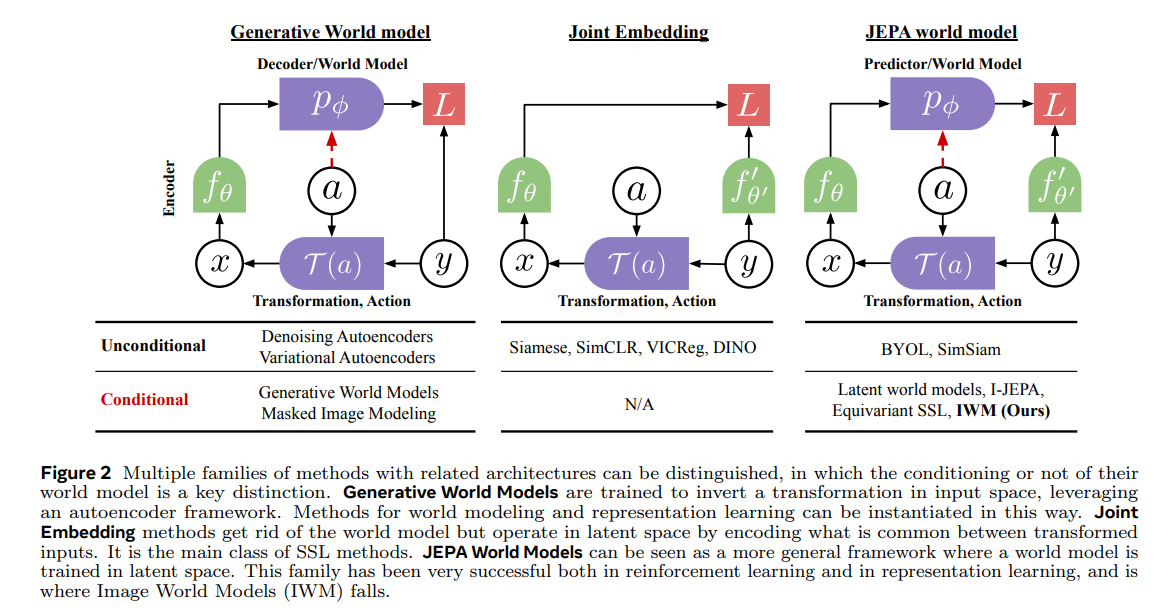
This approach introduces Image World Models (IWM), extending the Joint-Embedding Predictive Architecture (JEPA) framework (shown in Figure 2). Unlike traditional masked image modeling, IWM trains a predictor network to directly apply photometric transformations (like color shifts, brightness changes, etc.) to image representations within latent space.
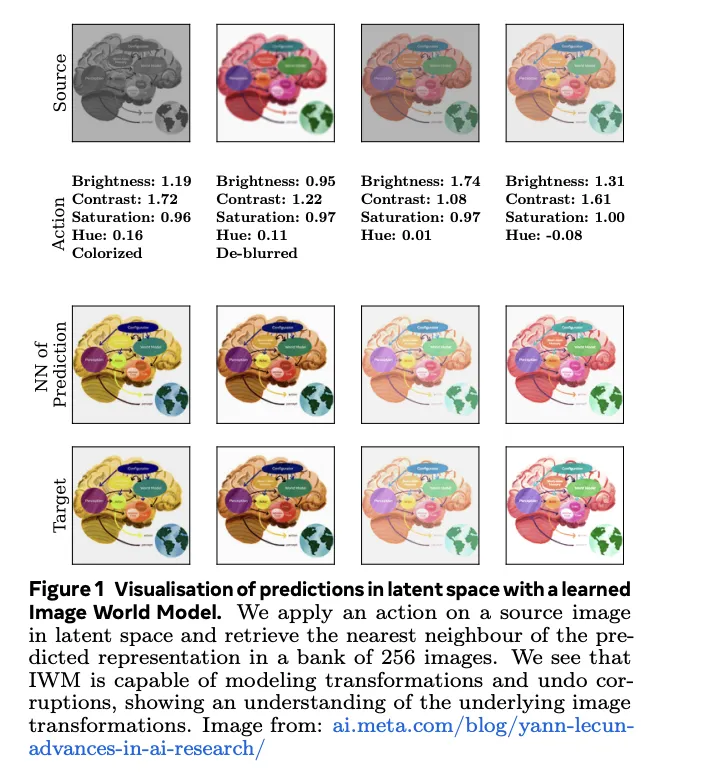
To train an IWM, researchers start with an image and generate two distinct views. The first view preserves maximum information through random cropping, flipping, and color jitters. The second view undergoes further augmentations like grayscale, blur, and masking. Both views pass through an encoder network to obtain latent representations. The crux of IWM lies in its predictor network, which attempts to reconstruct the first view’s representation by applying transformations in latent space (shown in Figure 1). Importantly, the predictor receives information about the specific transformations applied, allowing it to tailor its actions.
Researchers discovered several key factors crucial to building a capable IWM predictor. How the predictor receives and processes information about the transformations, the strength of those transformations, and the predictor’s overall capacity (size and depth) all play vital roles. A strong IWM predictor learns equivariant representations, allowing it to understand and apply image changes effectively. Conversely, weaker models tend to learn invariant representations that focus on high-level image semantics. This creates an intriguing tradeoff, allowing flexibility in the kind of representations the model learns.
Remarkably, finetuning the IWM predictor on downstream tasks (image classification, segmentation, etc.) not only yields significant performance advantages over simply finetuning the encoder but also does so at a notably lower computational cost. This finding hints at a potentially more efficient way to adapt visual representations to new problems, which could have profound implications for the practical application of computer vision.
This exploration of Image World Models suggests that the predictive component in self-supervised learning holds valuable and often untapped potential and offers a promising path to better performance in various computer vision tasks. The flexibility in representation learning and the significant boost in efficiency and adaptability through predictor finetuning could revolutionize vision-based applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
